Community resources
Community resources
Community resources
Security Operations with Jira and Confluence
 |
A Step-by-Step Guide to create a robust operation framework using Atlassian products Jira and Confluence. Implementation scenario is single-tier security operations team operating from one geographic region.
|
High level design
Situation is that we are creating the Security Operation team. This team will ingest alerts from different systems, reply to security concerns from internal and external folks and respond to phishing reports. If Alert or report is be True Positive, team is leading the incident investigation, asserting the mitigation steps and conducting proper post incident process.
It will not be covered here, but you can extend functionality of your SOC with Vulnerability management, Threat Intelligence, Security Engineering or Detection Engineering.
This is a guide on how to set up a great Security Operation Center (SOC) exactly for that.
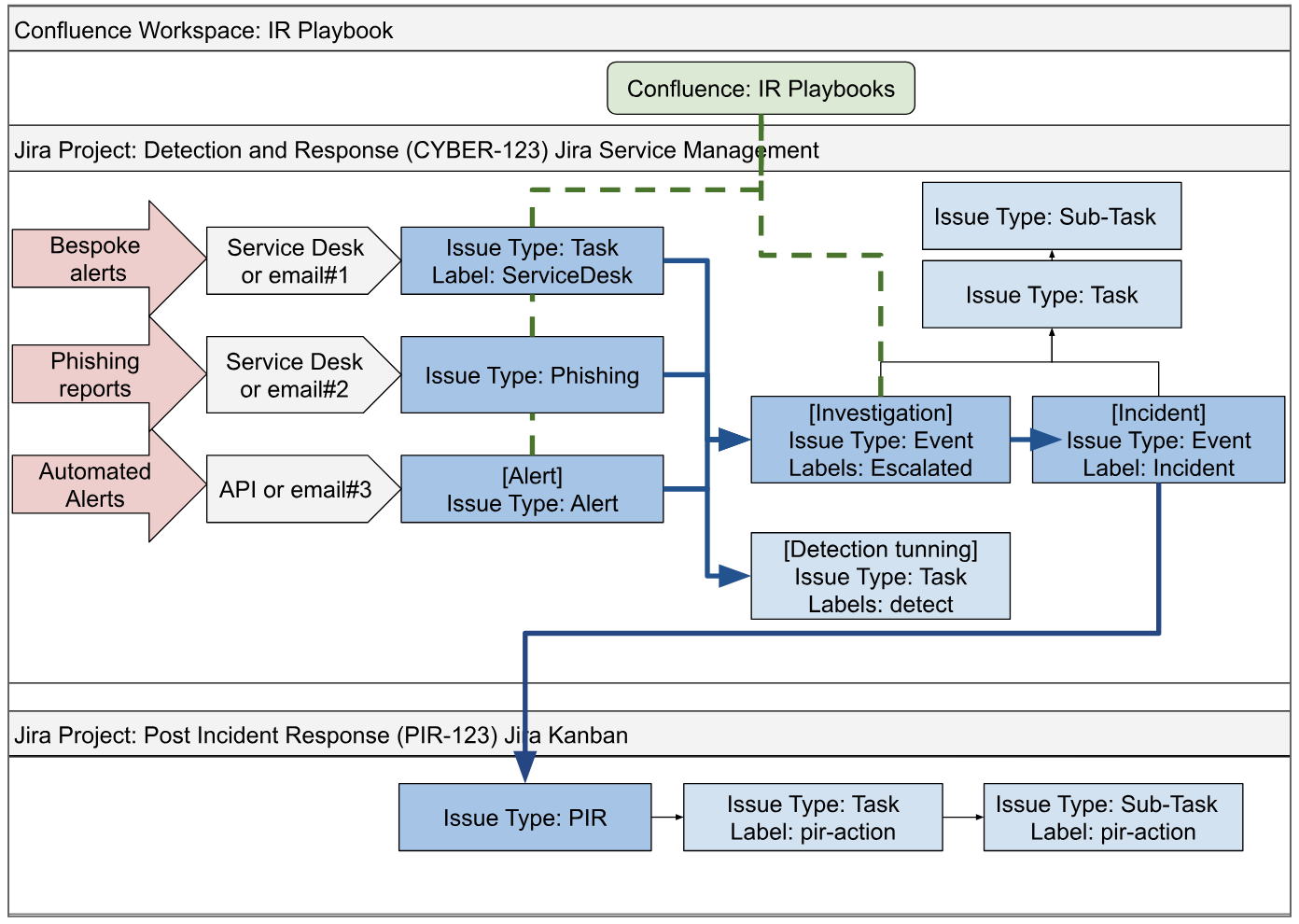
Our SOC will deploy is based on a one Confluence Workspace called Incident Response and two Jira projects. Jira project called CYBER is type Service Management and project PIR is type Kanban. See image below how these elements maps to Incident lifecycle.

Confluence page will serve as go-to place for Incident Response Playbooks and documentations. That maps to the Documentation/Preparation incident stage. Project Cyber handles Alerts, Investigations and Incidents. That is Detection, Analysis, Containment, Eradication and Recovery. Lastly, all root causes are recorded as follow-up actions in Project PIR.
High level workflow view
Alerts are systematically dispatched to the service desk or a designated email address, starting from the left. Alerts are linked to an investigation tickets, which can be escalated to incidents or associated with tuning requests. The Incident Commander is responsible for creating tasks and subtasks that correspond to the main incident ticket. Once the incident is resolved, a Post Incident Review (PIR) task is automatically generated to ensure a thorough Post Incident Process is conducted.
IR Playbooks are used to guide investigation of alerts and Incident Management.
Define Jira and Confluence structure
We will outline the specifics of each involved component.
Confluence: Security Incident Response Workspace
We refers to the content of Confluence workspace holding the IR Playbook, documentation and records of past incidents. All these are leveraged for preparation for handling security incidents. Incident Response analysts contributes to the content through the following actions:
-
Documenting all significant incidents (Security Incidents)
-
Developing and refining Incident Response documentation (IR Incident Playbook & OP Procedures)
-
Creating and updating documentation for incident response tools (Tools and Services)
-
Implementing lessons learned from past incidents within the Post Incident Review (PIR) process
Metrics, goals and SLOs shall be defined by Security Operation leadership.

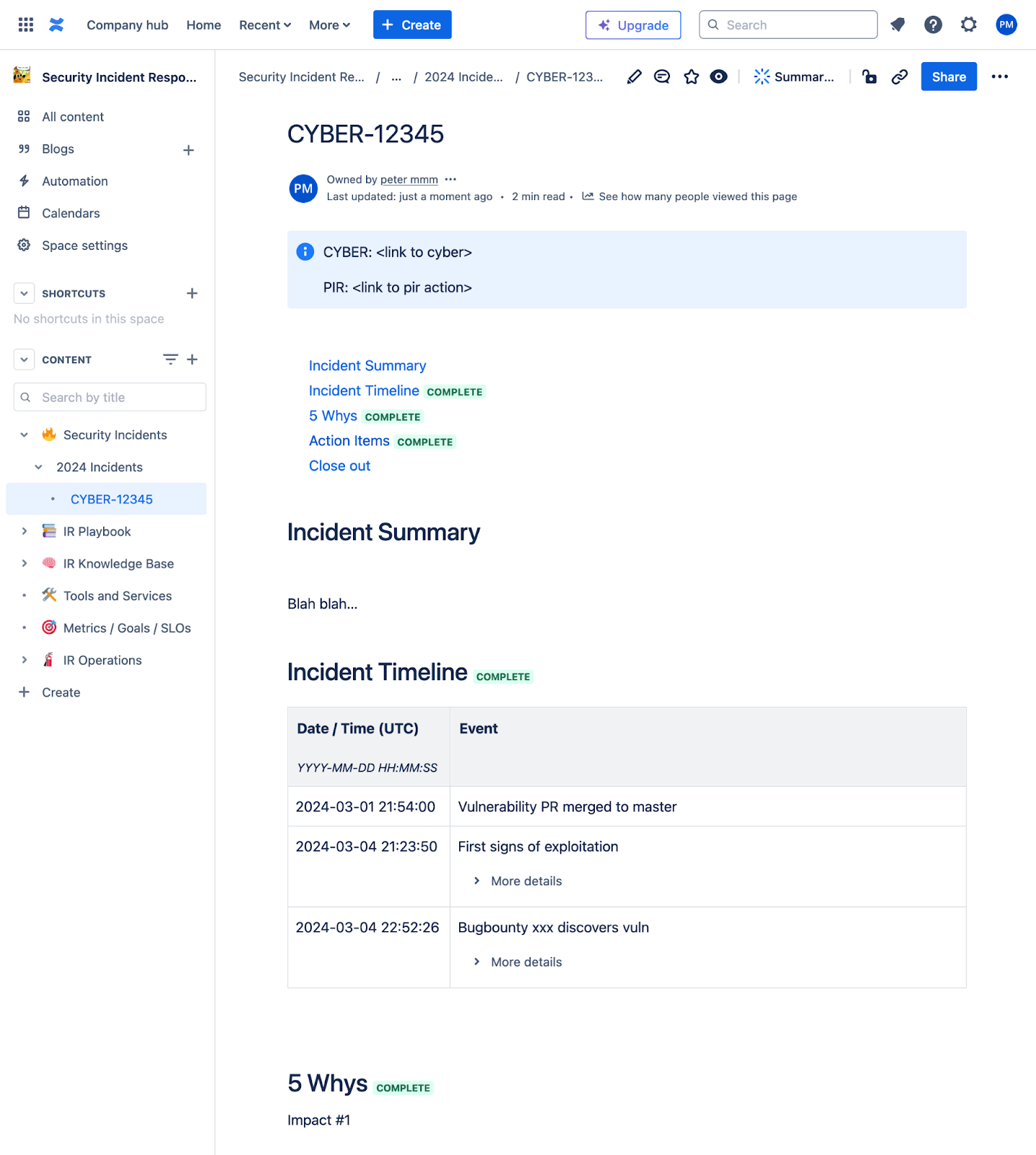
Directory: Security Incidents
The document will encompass comprehensive details regarding various incidents, the decisions made in response to them, as well as the actions taken during the Post-Incident Review (PIR). This document aims to provide a thorough understanding of the events that transpired, the rationale behind the decisions, and the subsequent evaluations that followed.
Proposed Document Structure:
-
Incident Summary: This section will provide a concise overview of the incidents, highlighting the key facts and context surrounding each event. It will serve as an introduction to the details that follow.
-
Incident Timeline: Here, a chronological account of the incidents will be presented, detailing the sequence of events as they unfolded. This timeline will help in understanding the progression and development of each incident.
-
5 Whys Analysis: In this part, the root causes of the incidents will be explored through the 5 Whys technique. This analytical approach will aid in identifying the underlying issues that contributed to the incidents, ensuring that similar situations can be mitigated in the future.
-
Action Items: This section will outline the specific actions that have been decided upon to address the findings from the incidents and the PIR. It will include both immediate and long-term measures aimed at improving processes and preventing recurrence.
-
Closure: Finally, the document will conclude with a summary of the overall findings and the effectiveness of the actions taken. This closure will encapsulate the lessons learned and the next steps to be taken moving forward, ensuring that the organization is better equipped to handle future incidents.
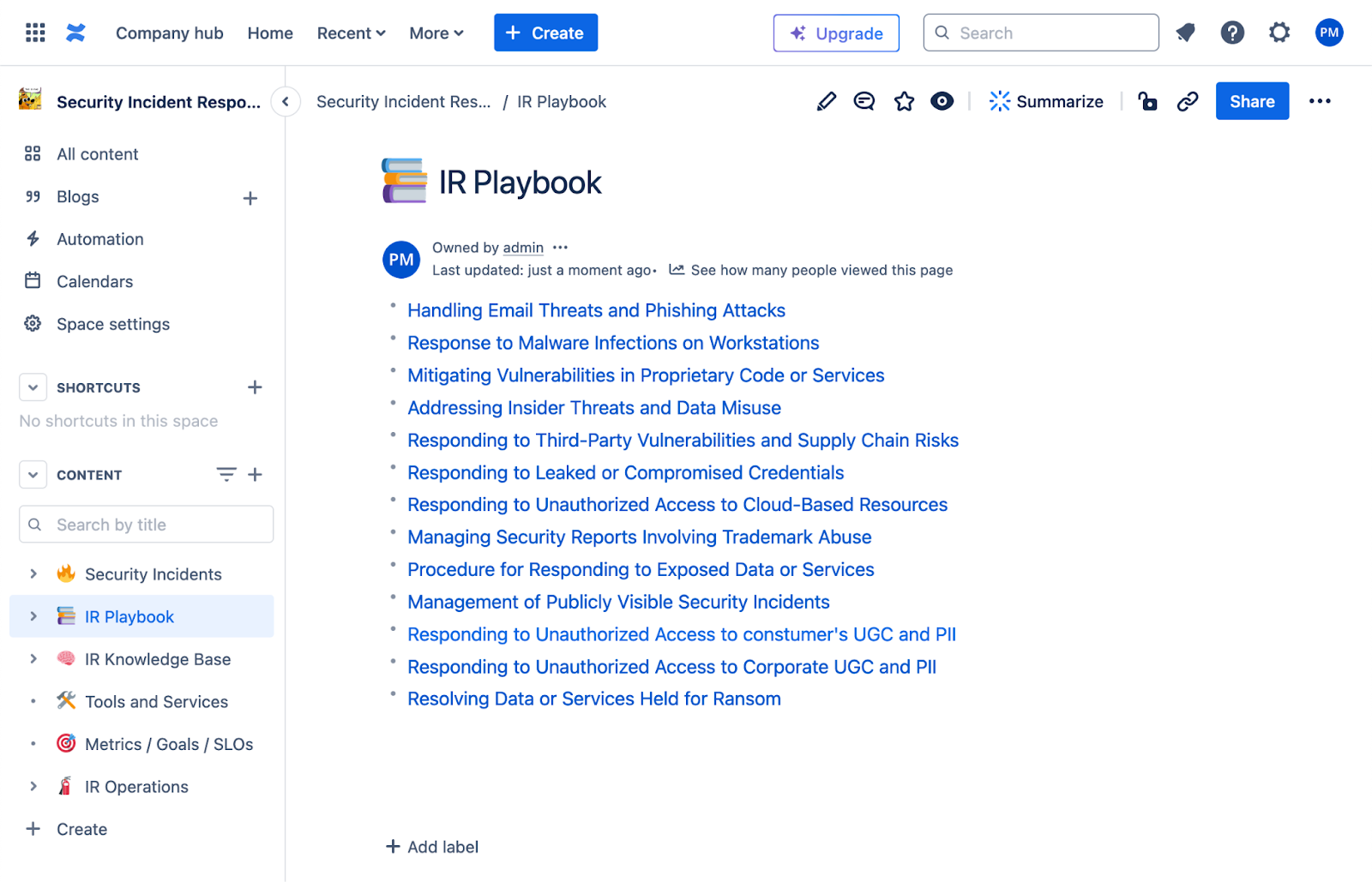
Directory: IR Playbook
The Incident Response Playbook serves as a crucial document that is intricately linked to the various input events that occur within an organisation. This playbook is not just a static resource; it is actively maintained and regularly updated to reflect the latest protocols and procedures. All of this information is housed within Confluence, a platform that facilitates collaboration and documentation. By being actively maintained within Confluence, the Incident Response Playbook ensures that all team members have access to the most current and relevant information, thereby enhancing the organisation's ability to respond effectively to incidents as they arise.
Example structure of IR Playbook:
-
Handling Email Threats and Phishing Attacks
-
Response to Malware Infections on Workstations
-
Mitigating Vulnerabilities in Proprietary Code or Services
-
Addressing Insider Threats and Data Misuse
-
Responding to Third-Party Vulnerabilities and Supply Chain Risks
-
Responding to Leaked or Compromised Credentials
-
Responding to Unauthorized Access to Cloud-Based Resources
-
Managing Security Reports Involving Trademark Abuse
-
Procedure for Responding to Exposed Data or Services
-
Management of Publicly Visible Security Incidents
-
Responding to Unauthorized Access to customer's UGC and PII
-
Responding to Unauthorized Access to corporate UGC and PII
-
Resolving Data or Services Held for Ransom
Directory: IR Knowledge Base
Knowledge base and operational Directives are essentially a set of rules and processes that are typically established for the purposes of compliance, privacy, or legal reasons. These guidelines are structured to ensure that an organization's operations align with relevant regulations, safeguard privacy, and adhere to legal obligations, thereby mitigating risks of non-compliance and potential legal challenges.
These directives are designed to be broadly applicable across a wide range of incident types, with specific conditions outlined for their activation. This means that regardless of the nature of an incident, there are predefined protocols in place that dictate the appropriate response measures. The conditions for triggering these directives are carefully defined within the operational framework, ensuring that responses are both timely and relevant to the situation at hand.
For example, in the event of a publicly exposed incident, an Operational Directive might specify the immediate steps for containing the public exposure, the process for notifying key teams. The directive would be triggered by the identification of public exposure, and its application would be mandatory, ensuring a consistent and legally compliant incident response.
Similarly, in scenarios involving compliance with regulations such as GDPR (General Data Protection Regulation) or HIPAA (Health Insurance Portability and Accountability Act), Operational Directives provide clear guidelines for managing personal data, responding to data access requests, and reporting breaches to regulatory authorities. These rules and processes are critical for maintaining compliance and protecting the organization from potential fines and reputational damage.
In essence, Operational Directives serve as a comprehensive playbook that guides organizations through the complexities of legal, privacy, and compliance landscapes. By establishing clear, actionable protocols that are triggered under specific conditions, organizations can ensure that their responses to various incidents are both effective and compliant with relevant laws and standards.
Directory: Tools and Services
The repository functions as a valuable resource, containing a diverse range of manuals and documentation tailored for the tools used by the security operations team. These tools include important elements such as SIEM (Security Information and Event Management), EDR (Endpoint Detection and Response), and SOAR (Security Orchestration, Automation, and Response). This comprehensive collection is important for providing team members with the information and guidance needed to effectively use these advanced tools in their daily tasks, thus contributing to the overall security posture of the organization.
Directory: Metrics / Goals/ SLOs
Proposed document structrure:
Key Performance Indicators (KPIs)
-
Definition: Define each KPI clearly and concisely.
-
Data Sources: Specify the data sources for each KPI (e.g., SIEM, EDR, vulnerability scanners, ticketing systems).
-
Measurement Frequency: Indicate how often each KPI will be measured (e.g., daily, weekly, monthly).
Service Level Objectives (SLOs)
-
Definition: For each KPI, define corresponding SLOs with specific, measurable, achievable, relevant, and time-bound (SMART) targets.
-
Error Budgets: Define acceptable error budgets for each SLO.
-
Visualization: Consider using tables or charts to visually represent SLOs.
Goal Setting
-
Align with Strategic Objectives: Outline how the defined KPIs and SLOs align with the overall security strategy and business objectives.
-
Set Long-Term Goals: Define long-term goals for improving SOC performance based on the established KPIs and SLOs.
Monitoring and Reporting
-
Monitoring Procedures: Describe the procedures for collecting, analyzing, and monitoring KPI data.
-
Reporting Frequency: Specify the frequency of reporting on KPI and SLO performance (e.g., weekly, monthly, quarterly).
-
Reporting Channels: Define the channels for communicating performance reports to stakeholders (e.g., dashboards, email, meetings).
Continuous Improvement
-
Review and Adjustment: Describe the process for regularly reviewing and adjusting KPIs, SLOs, and goals based on performance data and changing business needs.
-
Root Cause Analysis: Explain how the SOC will conduct root cause analysis of incidents and near misses to identify areas for improvement.
-
Action Plan: Outline the process for developing and implementing action plans to address identified performance gaps.
Jira Project - CYBER
The primary project dedicated to Incident Response encompasses a variety of issue types that are critical for effective management and resolution of incidents. These issue types include Alert, Event, and Phishing. Each of these event types is intricately linked to a tailored workflow that has been specifically designed to address and meet the unique requirements associated with each type of incident.
Depiction of Workflow Scheme:
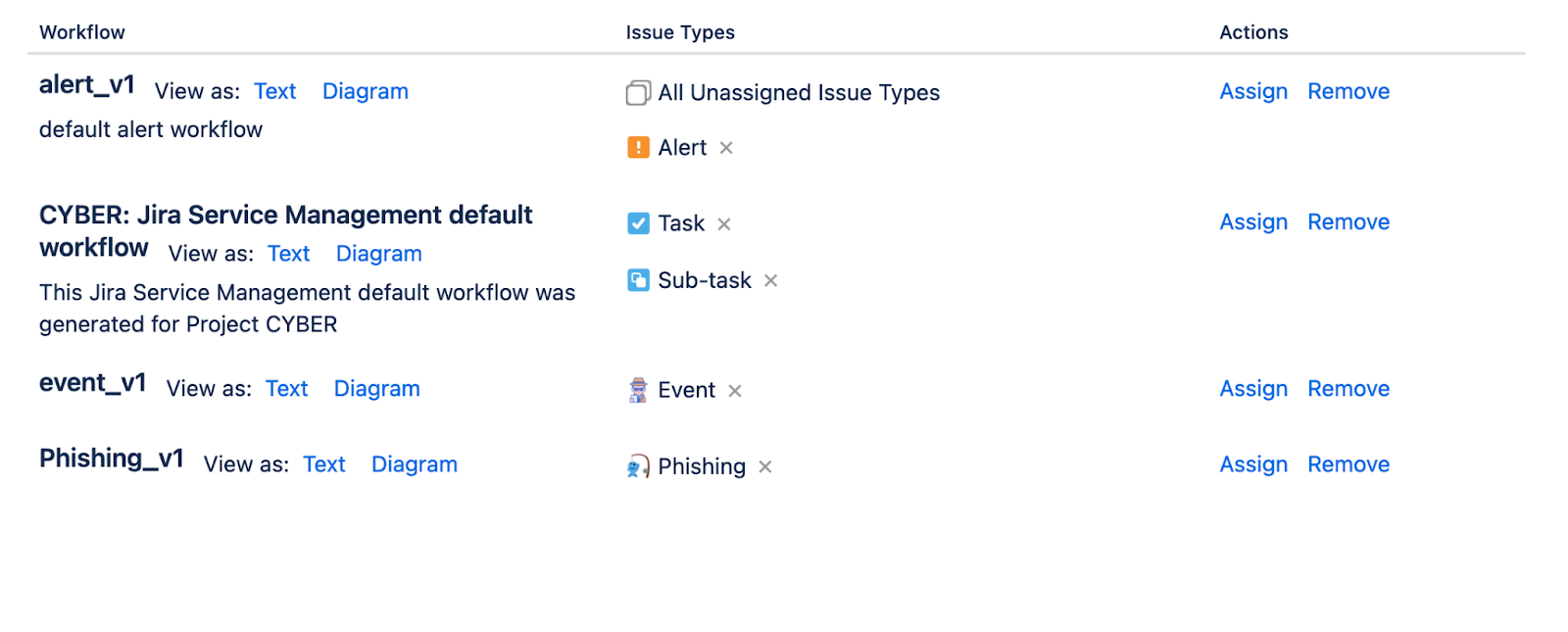
Issue Types in Detail
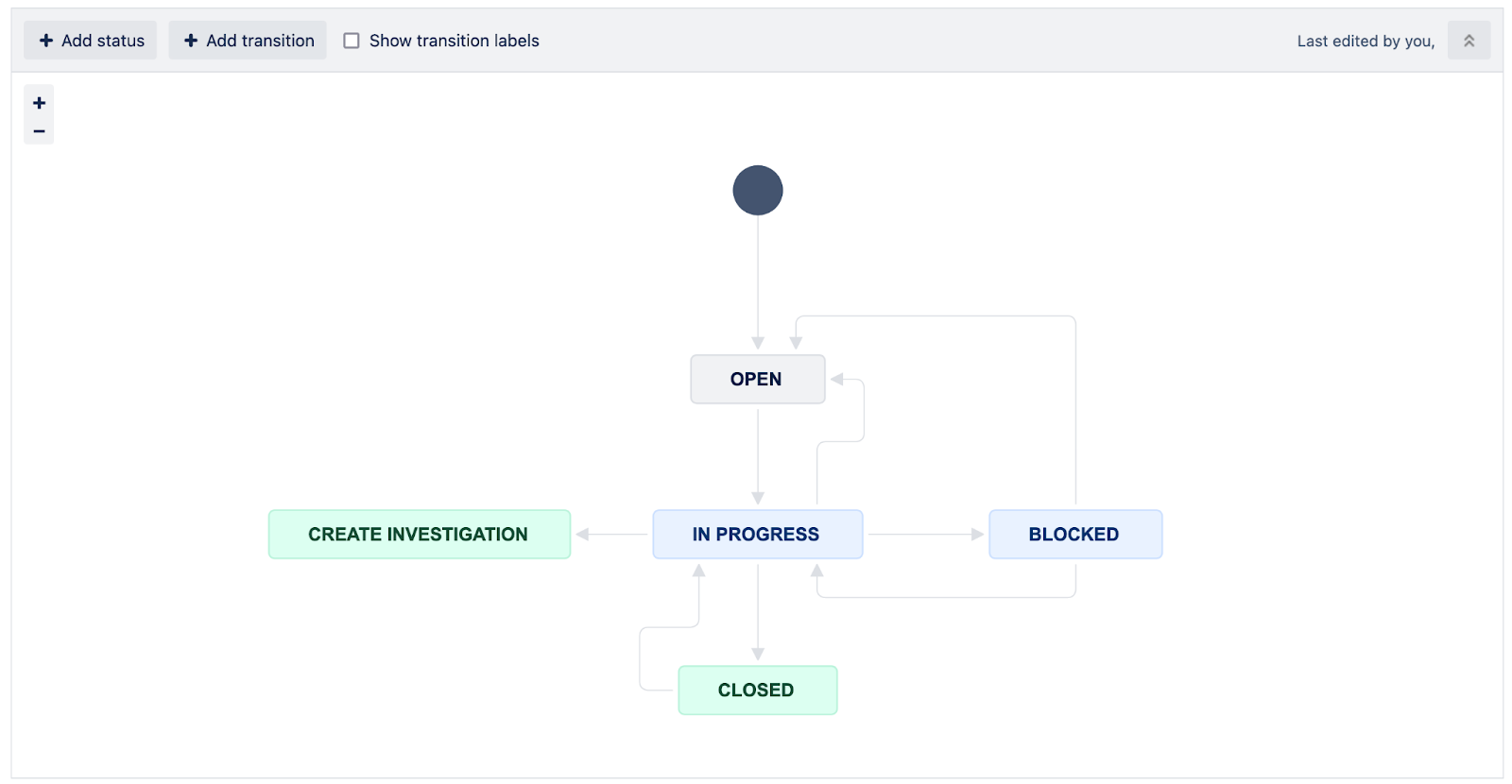
Issue Type: Alert
Alerts are generated by security controls such as Intrusion Detection Systems (IDS), Security Information and Event Management (SIEM), and AWS GuardDuty.
Aler’s final status is CLOSED or CREATE INVESTIGATION. Second one is an escalation of Alert to Event. Multiple Alerts can be linked to one Event.
Workflow:
Issue Type: Events
Events can be escalated from Alerts or reported manually. Events can be escalated to an Incident when necessary.
Final status for Event is Closed. Event can be escalated to the incident but that is not the final status.
Workflow depiction:

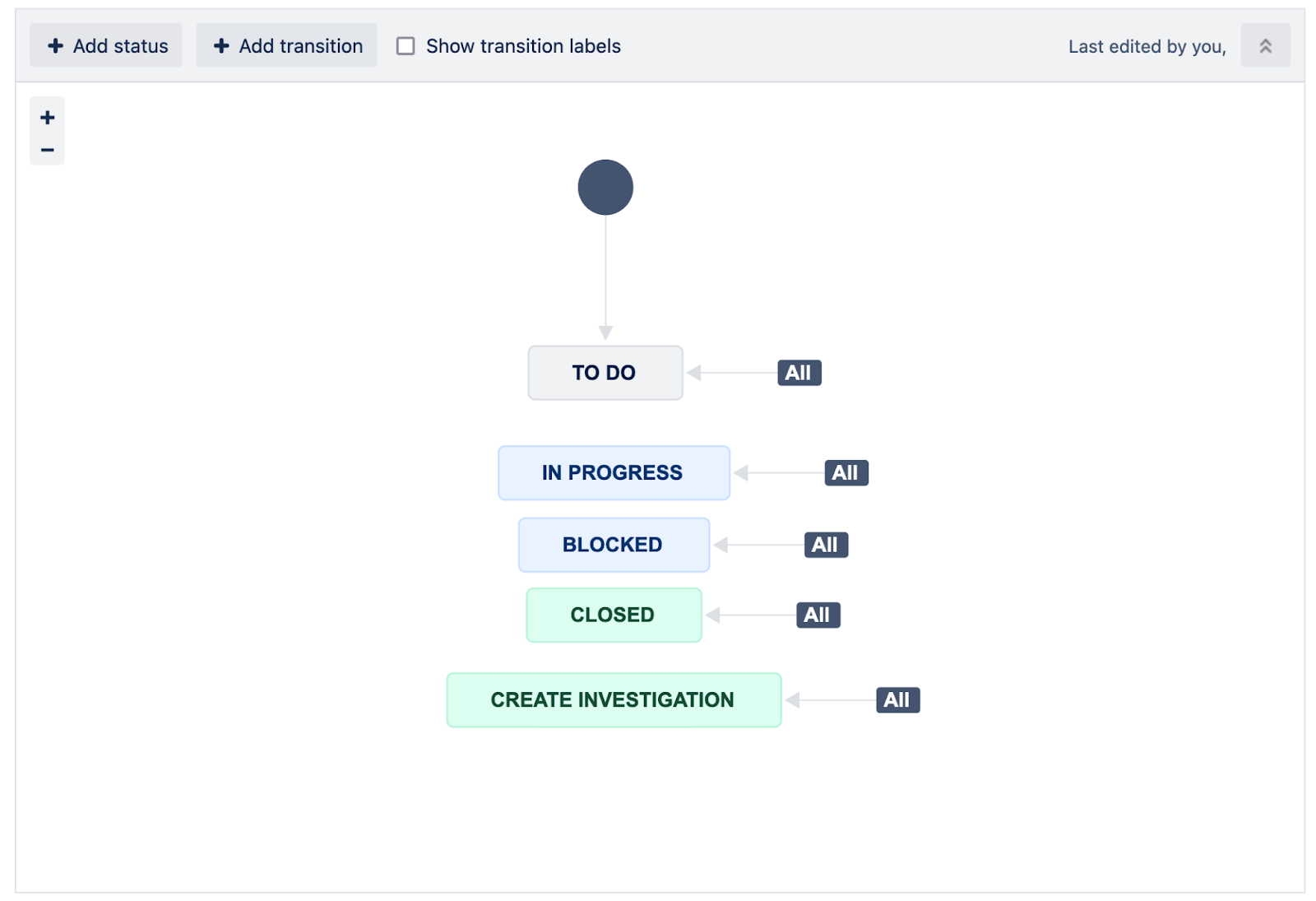
Issue Type: Phishing
Phishing attempts are reported via email by utilising the "Forward as attachment" feature to send them to designated email addresses.
Phishing has two final statuses - CLOSED or CREATE INVESTIGATION. Later one is automatically creating the security event. Multiple Phishing report can be linked to one Event.
Workflow:
Request types
Request types help you categorize incoming requests and collect the details you need to resolve them.
Learn more about request types.
We will create two service requests visible on our Jira Service Desk for users. First for reporting security issues on our Service Desk and second for manual submission of phishing emails.

Report a Security Event
This request type is specifically designed for the manual reporting of security issues.
Report Phishing
This request type is utilised for phishing emails that have been reported either through the report button or forwarded to a designated email address.
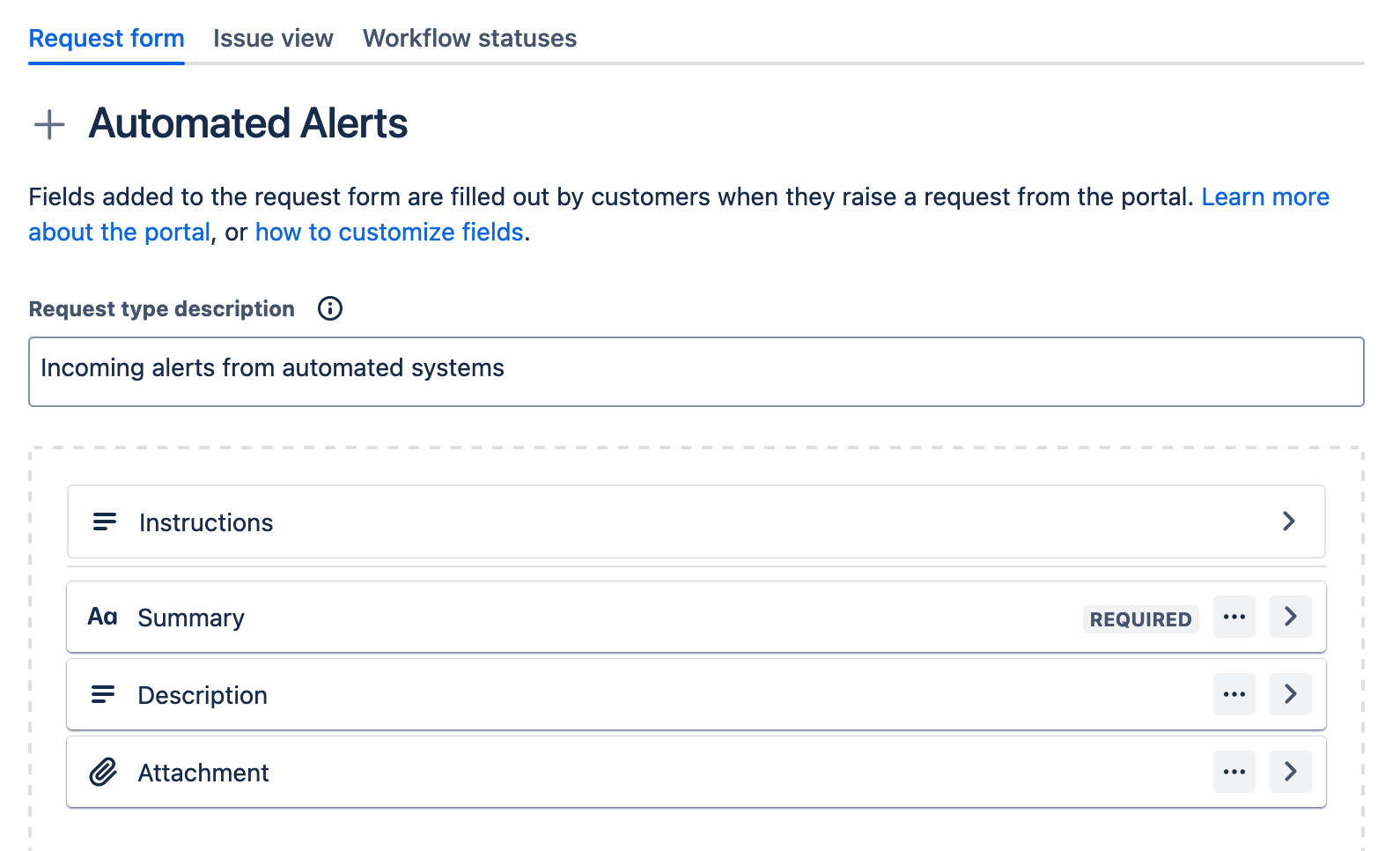
Automated Alerts
This is issue type for all automated alerts. It is not visible on the Service Desk.
Jira Project: Post Incident Response (PIR)
Post Incident Review (PIR ) is a written record of an incident that details its impact, the actions taken to mitigate or resolve it, the root cause(s), and the follow-up actions taken to prevent the incident from recurring.
You can read about PIR best practices here:  Post-incident review best practices | Jira Service Management Cloud | Atlassian Support
Post-incident review best practices | Jira Service Management Cloud | Atlassian Support
The goals of a PIR are to understand all contributing root causes, document the incident for future reference and pattern discovery and enact effective preventive actions to reduce the likelihood or impact of recurrence. We follow the blameless approach for the root cause and preventive actions evaluation.
A PIR is considered successful if it mitigates the reoccurrence of an incident or class of incident. To achieve that outcome, High priority AIs are completed as soon as possible. Other Priority AIs are completed within prescribed SLOs
PIRs are coupled with an Incident's lifecycle. There are many to many relationships between a PIR and an Incident. In the majority of the cases, one incident corresponds to one PIR however.
All PIR creations are triggered by the incidents i.e. a PIR must be linked with at least one incident.
Issue Types
Issue Type PIR-Action
PIR action workflow contains backlog queue for easier sprint planning and review process.
Workflow:

Deploy Automations Everywhere
Sucesfull adoption of automatons is crucial for operational effectivity. We will lay the foundation with automated escalations, creation of detection tuning tickets, automated phishing response and quided PIR process.
Escalation of Alert/Notification to Investigation
When issue is transitioned from Create Investigation state, create new security event. Close this alert and link it. If Event exist, link to existing event. Create comment in this alert with newly linked issue.
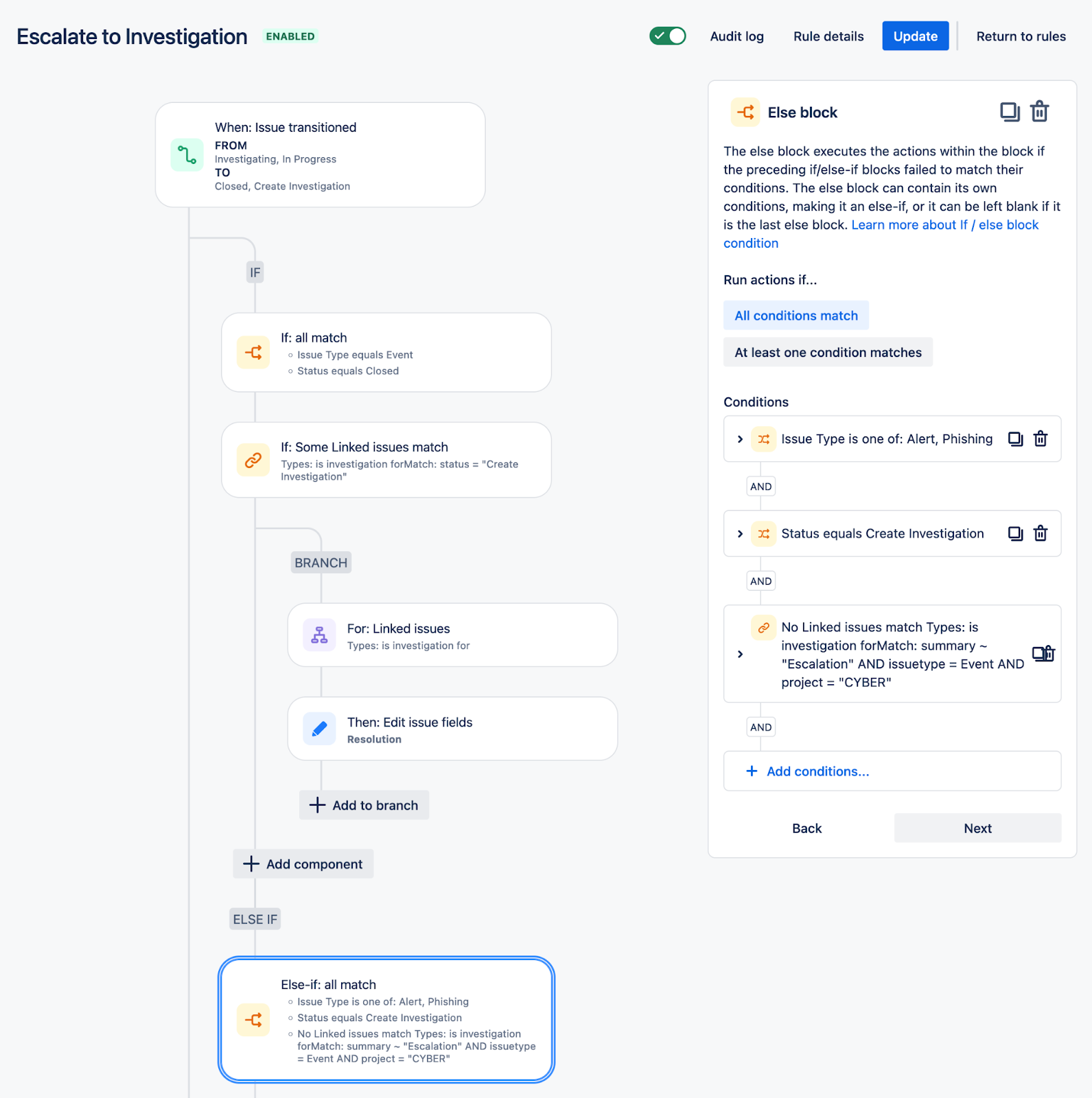
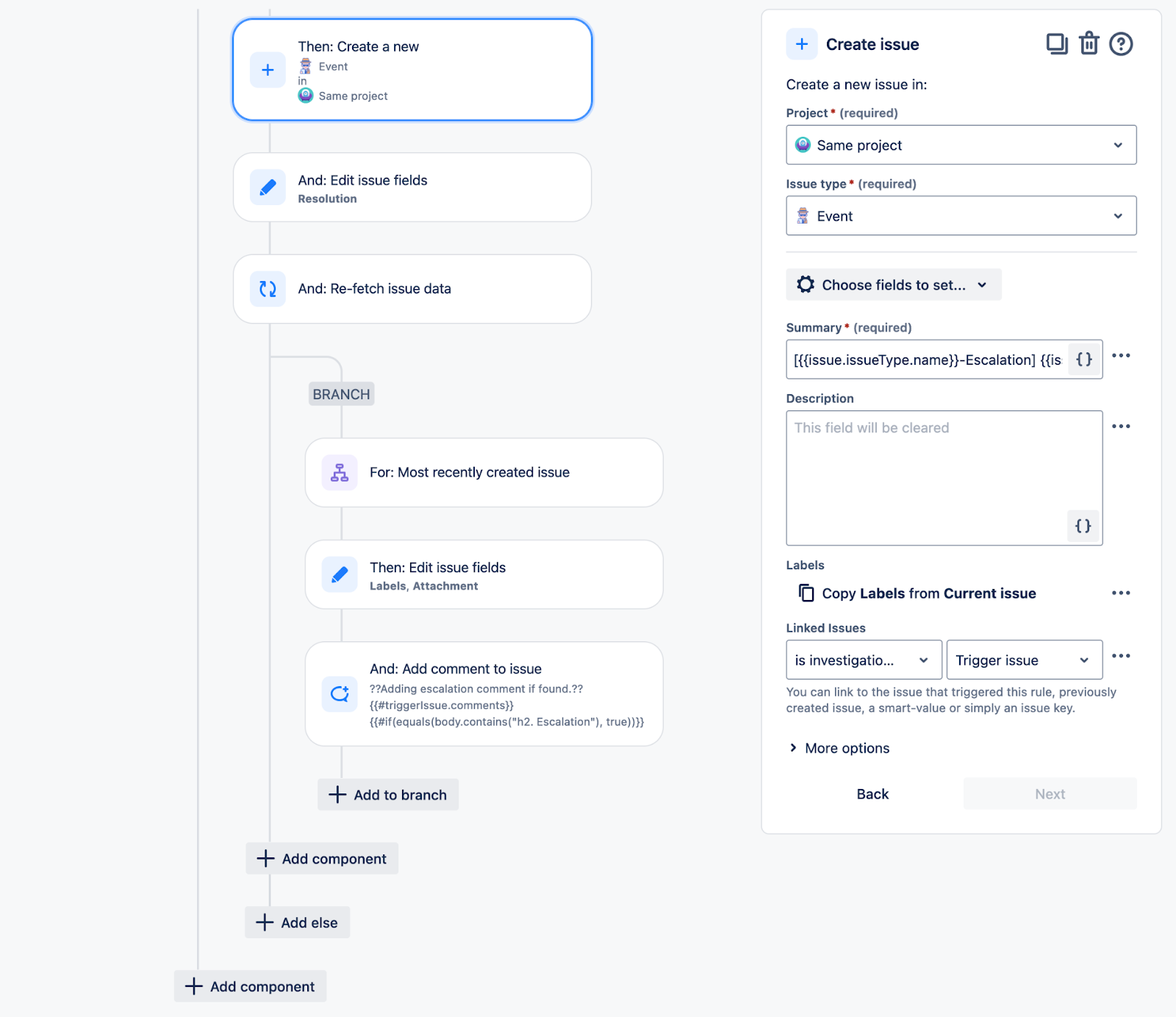
Escalation of Investigation to the Incident
This automation will create the Incident page in the Incident Response Confluence space and the Slack channel. Select your Security Operation group as Slack channel members.

Create Tuning ticket from Alert (Noise Reduction)
If the detection process is yielding noisy results, a tuning ticket for detection engineering should be generated. Additionally, if a similar request has been submitted in the past, link request to the existing ticket.
Depiction of Automation:
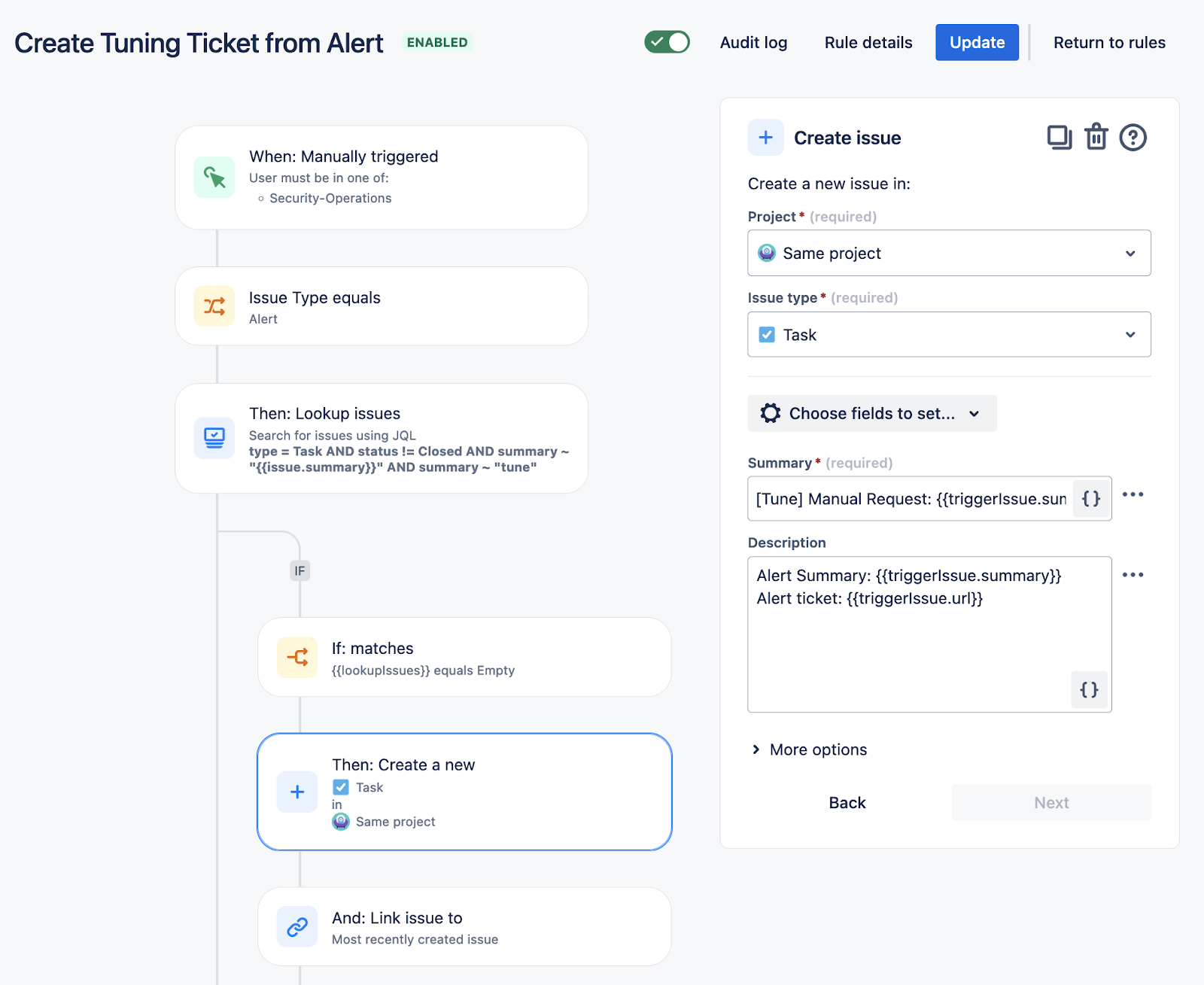
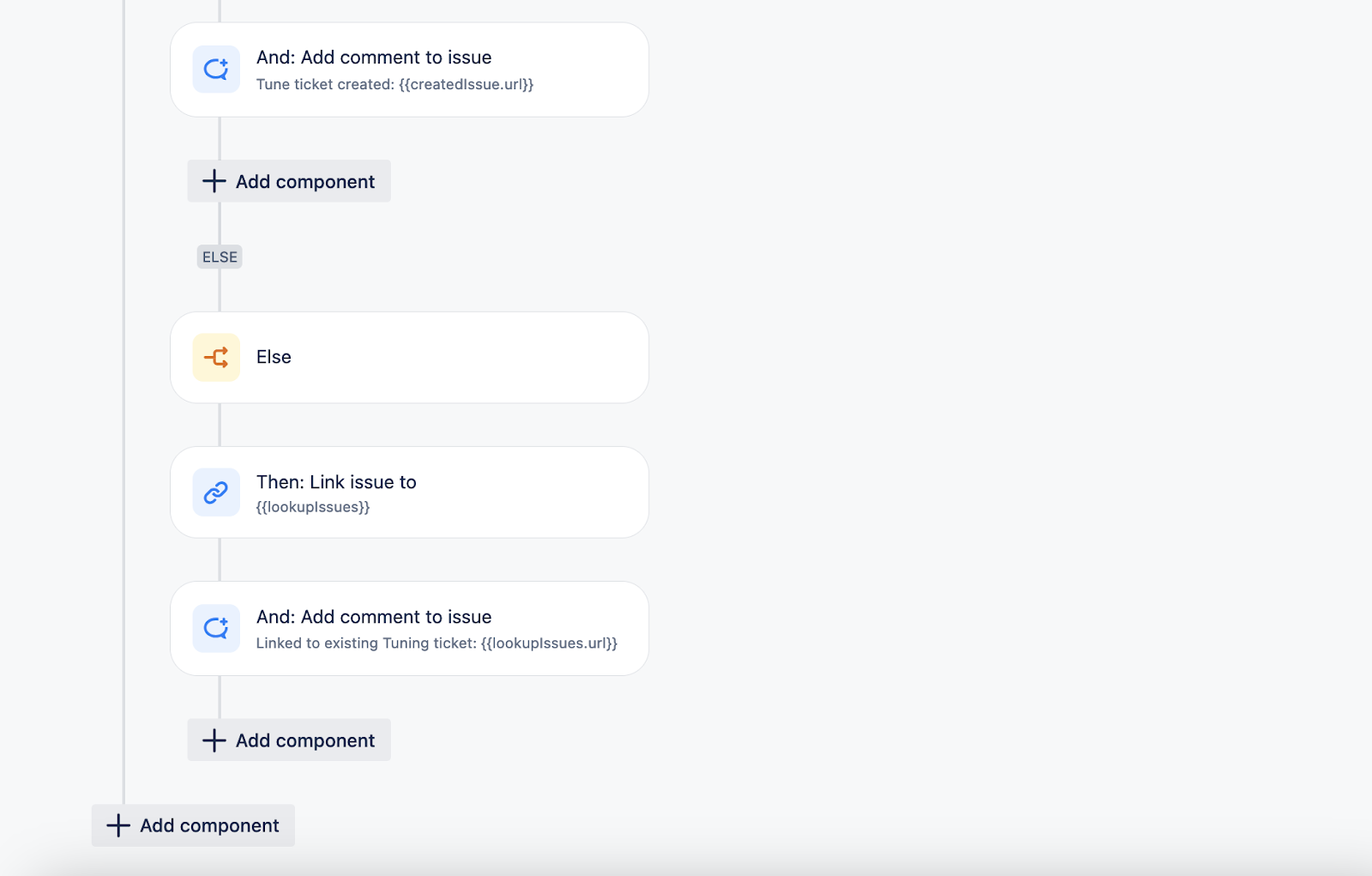
Automation is available as an action:

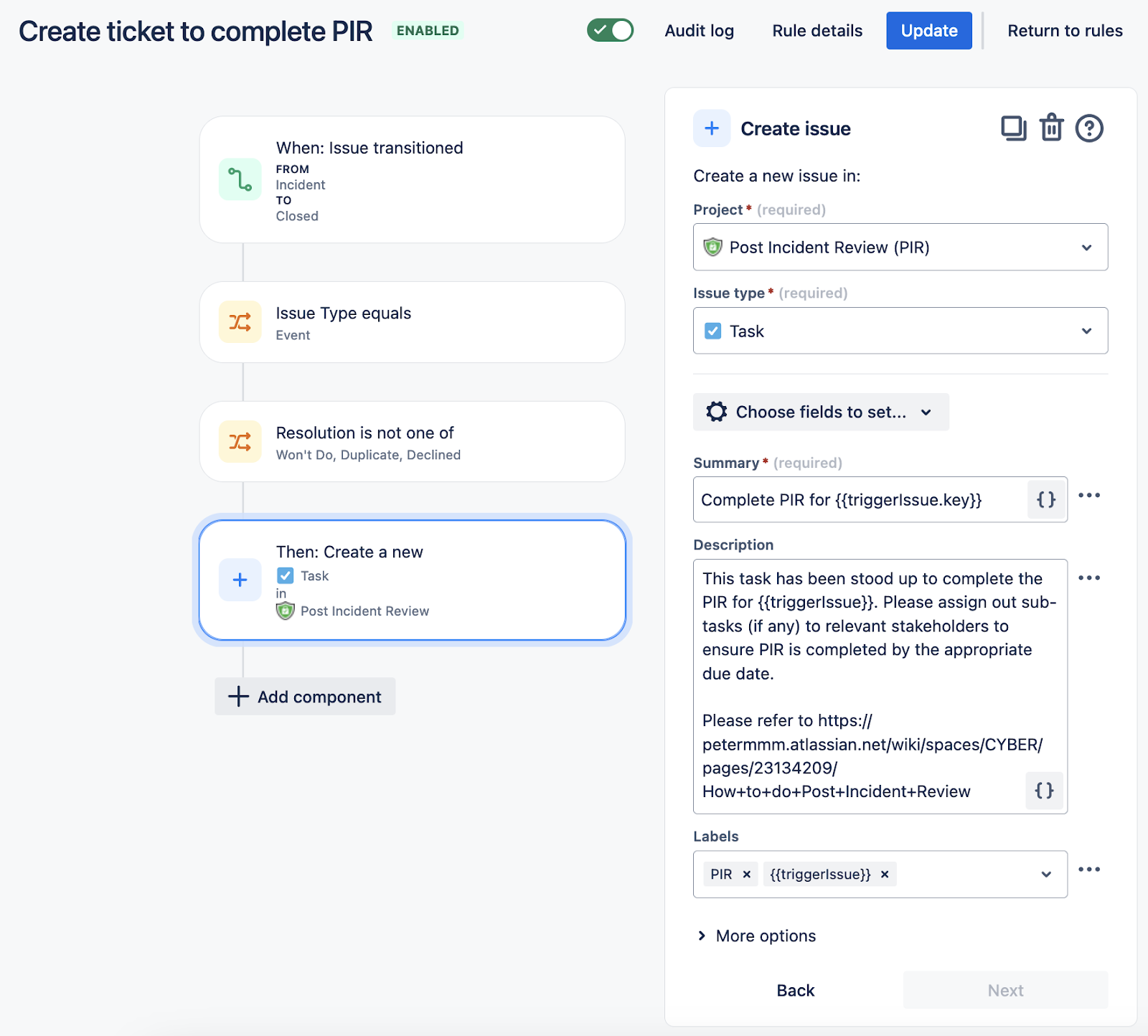
Create ticket to complete PIR after Incident close
Once incident is transitioned to the Closed status, create the PIR ticket with all the details in the description. Optionally , assign newly create ticket to currently assigned person from the incident ticket and set due date.
Depiction of Automation:
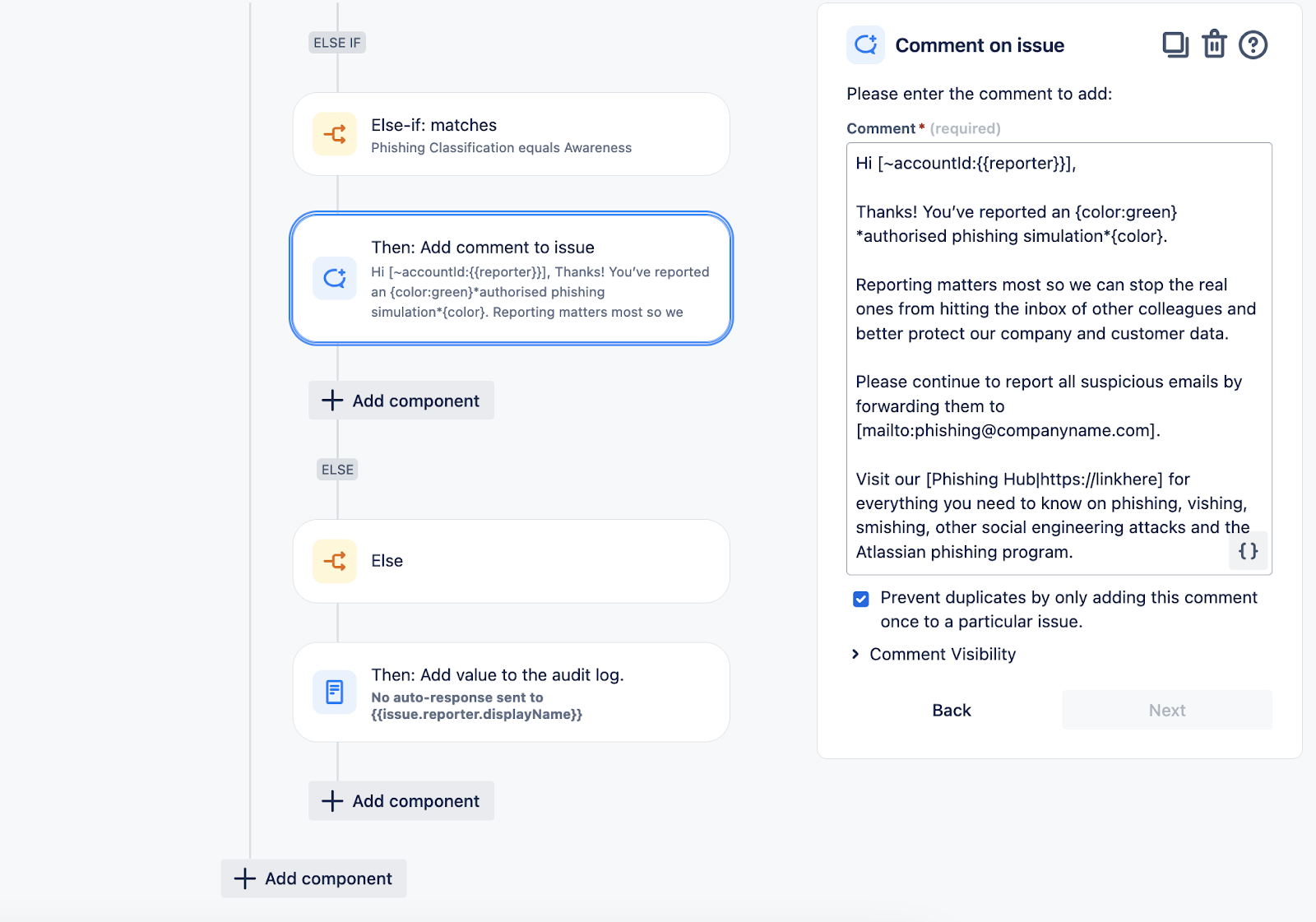
Auto-Respond to Reporter with Phishing Verdict
This automation will generate a templated response to phishing submissions according to the specified Phishing Classification field. A template is required for each classification option.
Depiction of Automation:
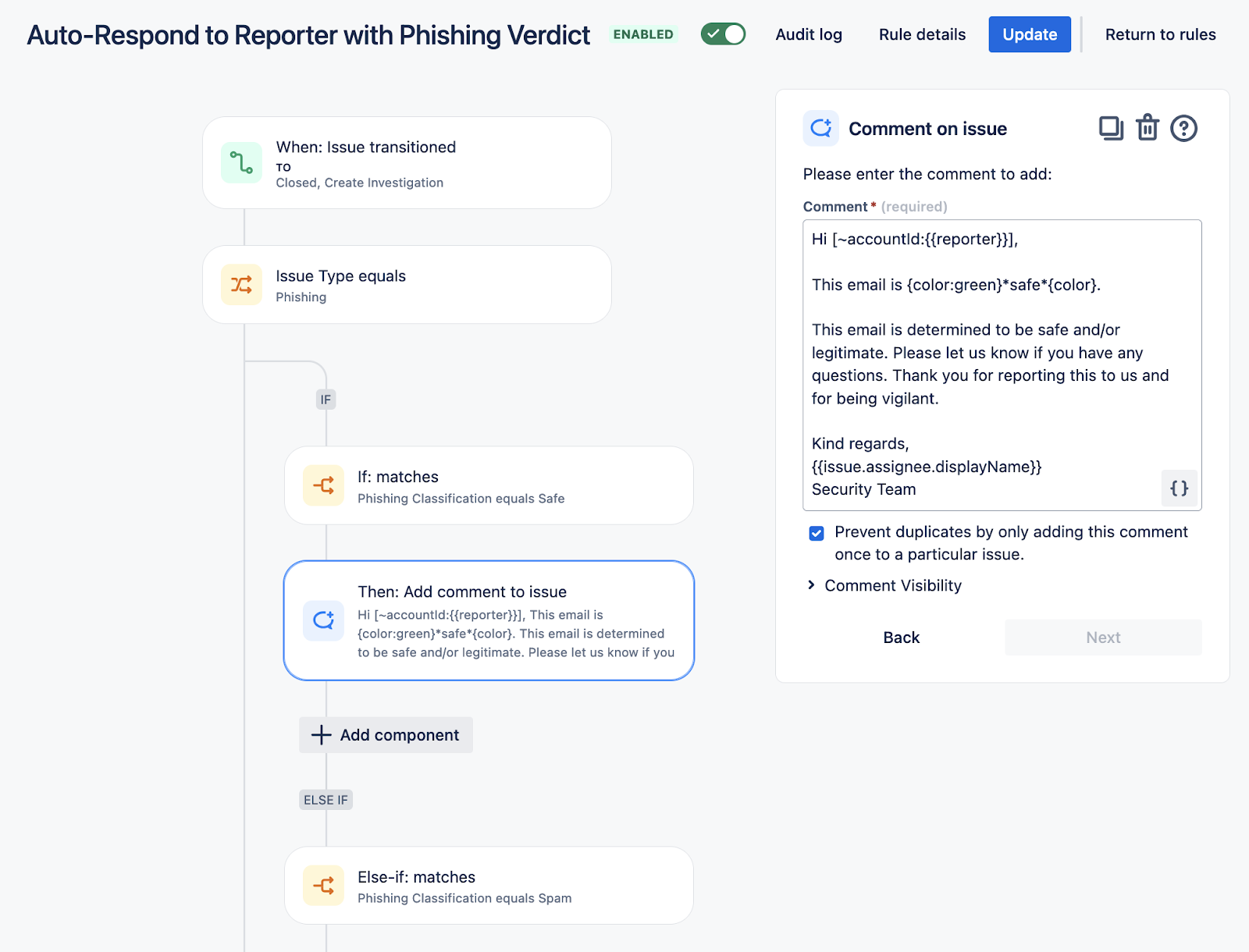
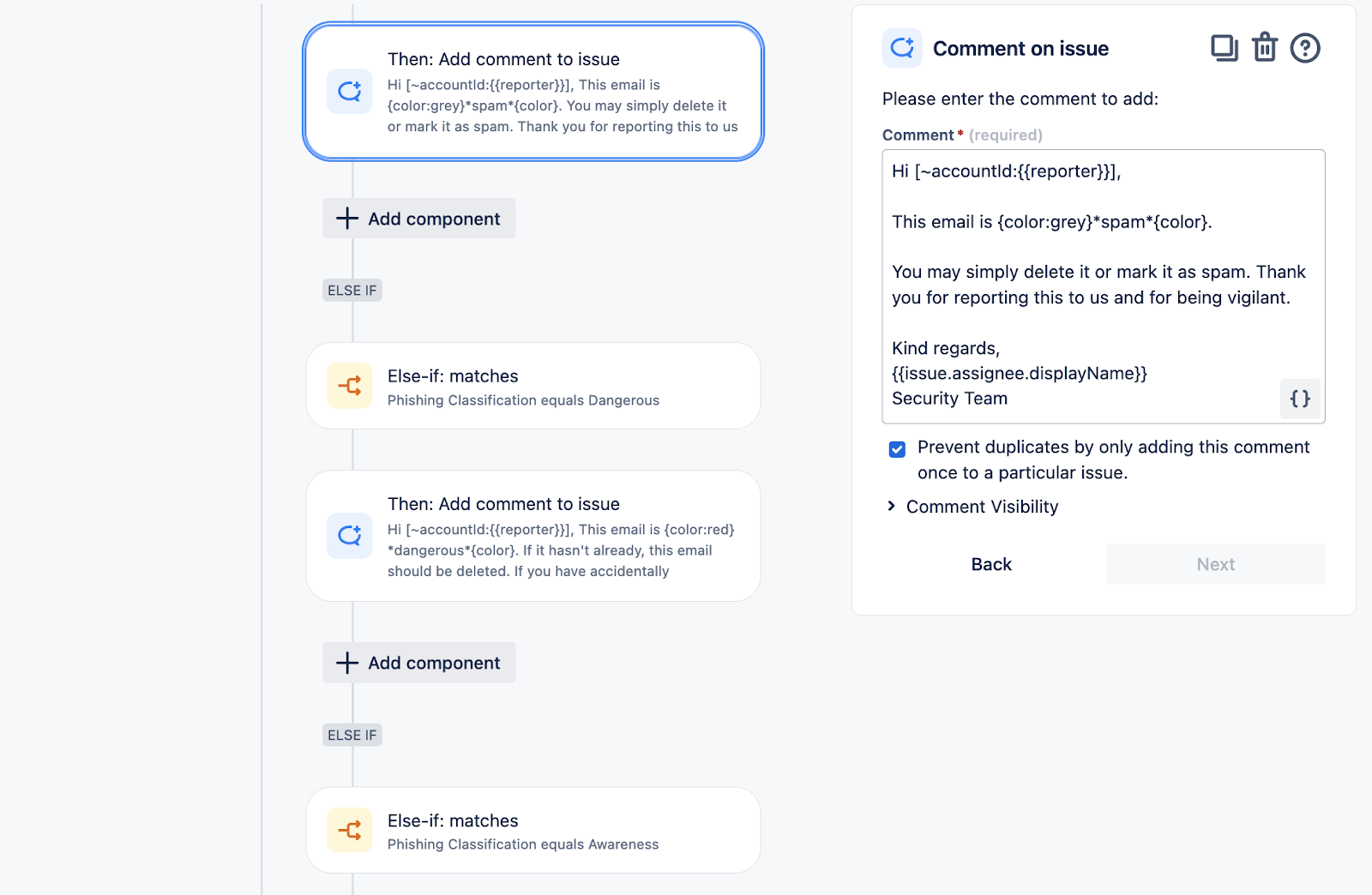
Parsing Email Attributes
Configure your phishing report button to forward email to your single-purpose email address. It is common configuration is that headers from reported emails are added to the body of the email and the full payload is attached as EML file.
Example of parsing automation using regex
From: {{issue.description.match("From: ([^\n\r]*)")}}
To: {{issue.description.match("To: ([^\n\r]*)")}}
Subject: {{issue.description.match("Subject: ([^\n\r]*)")}}
Authentication-results: {{issue.description.match("authentication-results: ([^\n\r]*)")}}
Arc-authentication-results: {{issue.description.match(".*arc-authentication-results:([^\n\r]*)")}}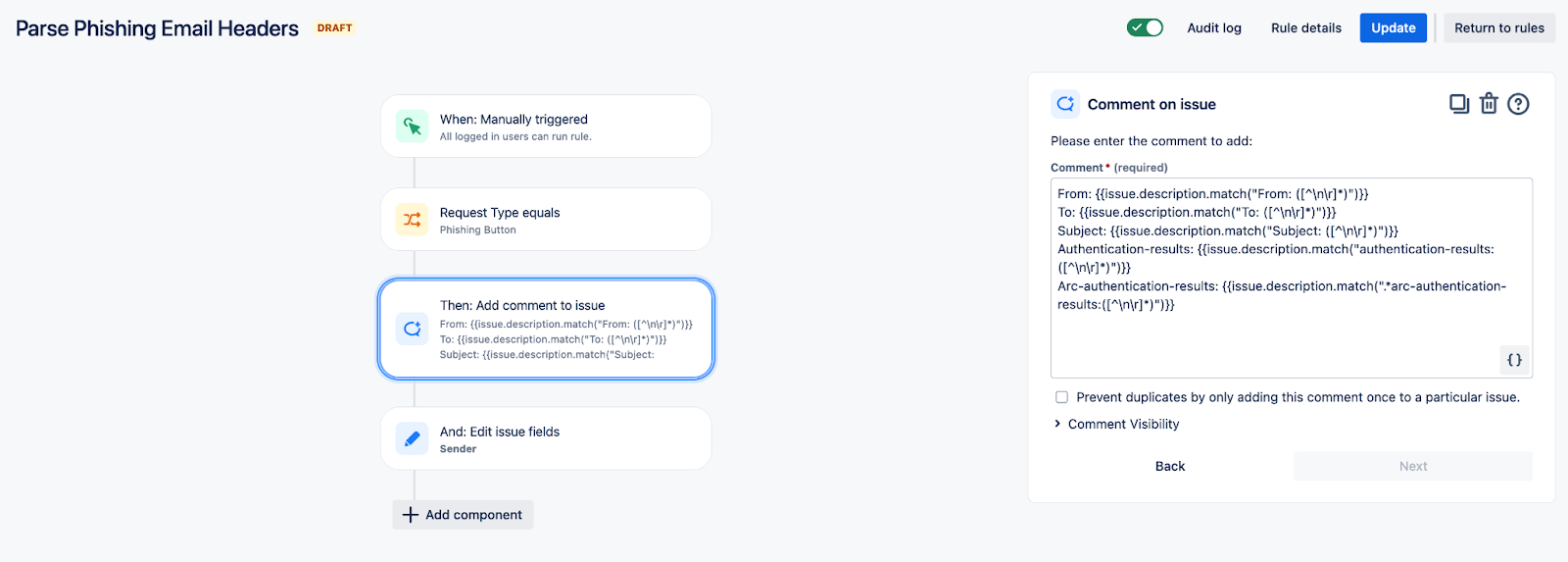
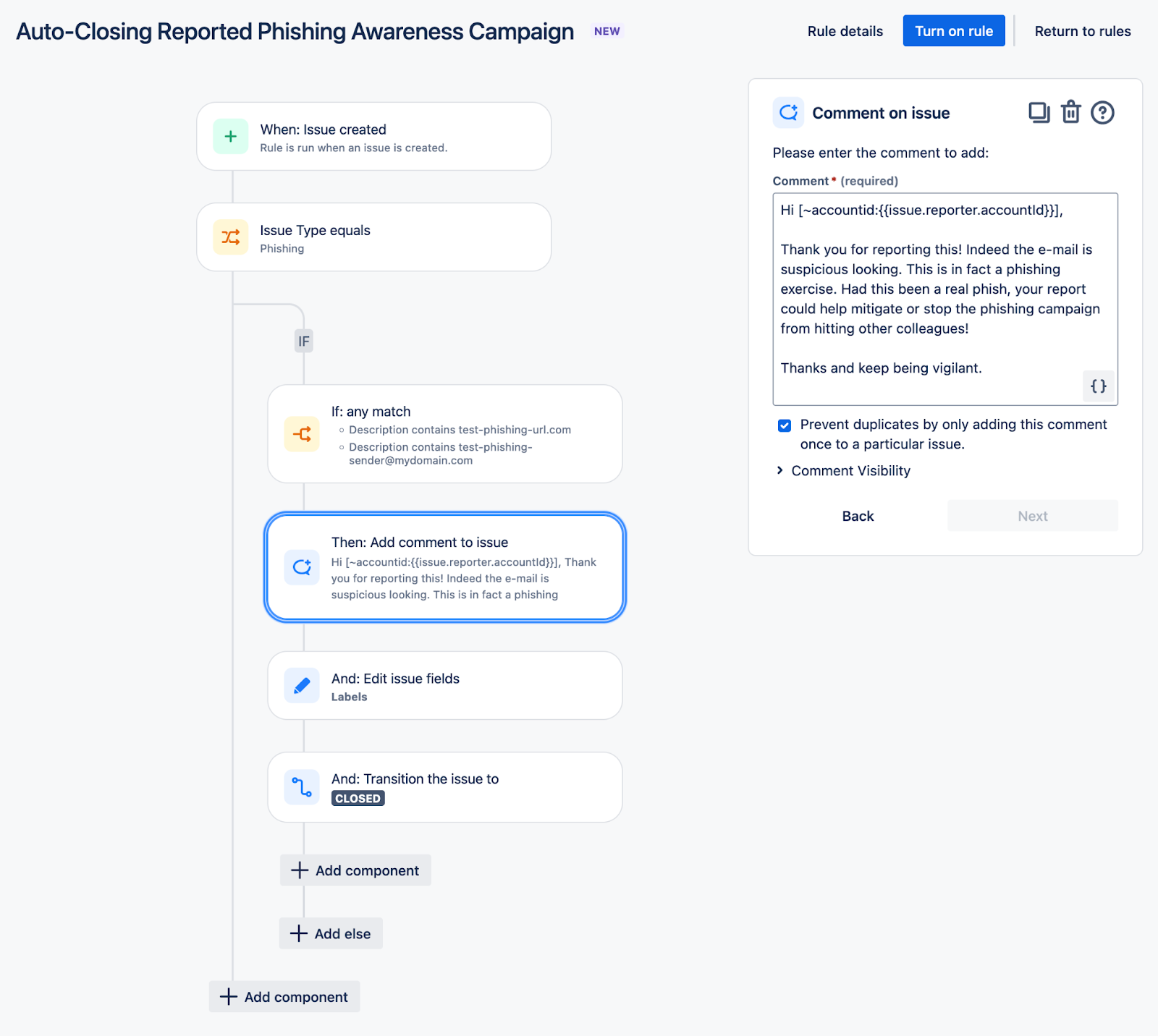
Auto-Closing Reported Phishing Awareness Campaign
This automation manages reported phishing emails that align with the ongoing awareness campaign. A reply is included as a comment in the ticket, and the issue is subsequently closed. The matching conditions should be updated to correspond exclusively to internal phishing campaigns.
Extending Abilities
Beyond the scope of this guide, you have the opportunity to create additional Jira projects and corresponding Confluence documentation for the following areas:
-
Vulnerability Management (VULN)
-
Threat Intelligence (CTI)
-
Security Engineering (SECENG)
-
Detection Engineering (DETECT)
Additionally, you can expand your operations to adopt a Follow the Sun model, allowing for continuous coverage.
Furthermore, consider organising your team for multi-tier operations to enhance efficiency and responsiveness.
The End.
Was this helpful?
Thanks!
Peter Matkovski

1 comment