Community resources
Community resources
Community resources
How to do DevOps
How to do DevOps
A step-by-step guide for teams who want to implement DevOps
.png?cdnVersion=529)
WARREN MARUSIAK
Senior Technical Evangelist
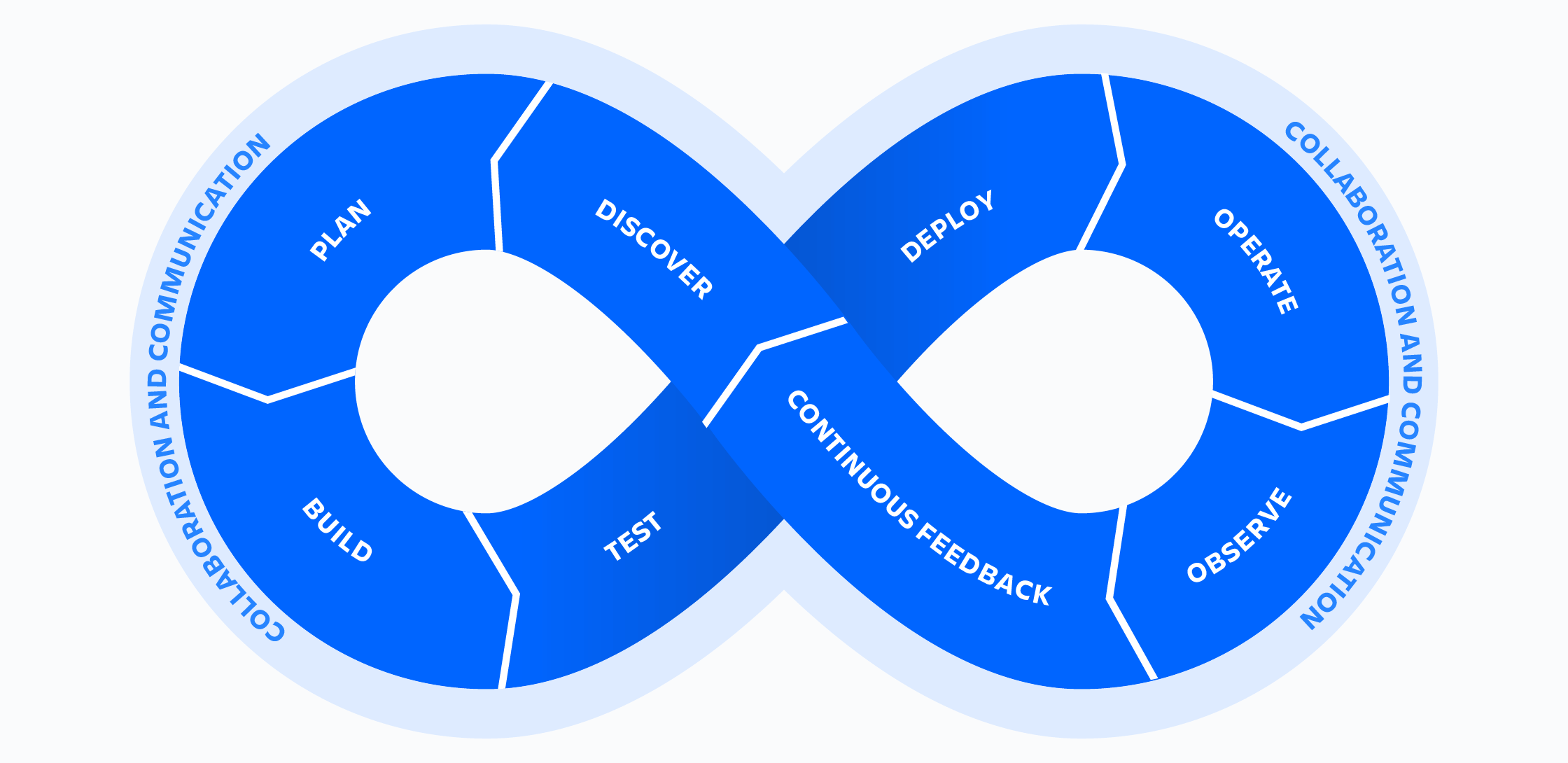
Is your software development lifecycle a confusing mess of tools and workflows? Are your teams and projects siloed? If you answered yes to either of these questions, it’s an excellent time to consider DevOps. DevOps helps simplify and optimize development and deployment workflows by creating a new software development ecosystem.
But how do you implement DevOps? One of the primary challenges of DevOps is that there’s no standard process since each team has different needs and goals. The sheer number of DevOps tools and resources can lead to “analysis paralysis,” that inhibits adoption. The following steps can help your team implement DevOps.
Why DevOps?
The short answer is that DevOps increases productivity by allowing developers to do what they do best: build fantastic software rather than manually performing low-value work like manually checking log files. DevOps practices automate repetitive work such as running tests and deployments, monitoring production software for problems, and building a problem-resilient deployment methodology. Developers are empowered to build and experiment, which leads to increased productivity.
There are many definitions for DevOps. In this article, DevOps means that a team owns the entire lifecycle of a piece of software. A DevOps team designs, implements, deploys, monitors, fixes problems, and updates software. It owns the code and the infrastructure the code runs on. It is not only responsible for the end-user experience but production problems.
A tenet of DevOps is to build a process that expects problems and empowers developers to respond to them effectively. A DevOps process should provide developers immediate feedback about the system's health after each deployment. The closer to inception a problem is discovered, the lower its impact and the sooner the team can progress to the next body of work. Developers can experiment, build, release, and try new ideas when it is easy to deploy changes and recover from problems.
What DevOps is not: technology. If you buy DevOps tools and call it DevOps, that’s putting the cart before the horse. The essence of DevOps is building a culture of shared responsibility, transparency, and faster feedback. Technology is simply a tool that enables this.
A disclaimer
Given that every team has a unique starting point, some of the following steps may not apply. Also, this list is not exhaustive. The steps presented here are meant as a starting point to help a team implement DevOps.
In this article, DevOps is used as a catch-all term for the culture, processes, and technologies that make DevOps work.
8 steps to DevOps
Step 1 - Pick a component
The first step is to start small. Pick a component that is currently in production. The ideal component has a simple code base with few dependencies and minimal infrastructure. This component will be a proving ground where the team cuts its teeth on implementing DevOps.
Step 2 - Consider adopting an agile methodology like scrum
DevOps often comes paired with an agile work methodology, such as scrum. It is not necessary to adopt all rituals and practices associated with a method like scrum. Three elements of scrum that are generally easy to adopt and quickly provide value are the backlog, sprint, and sprint planning.
A DevOps team can add and prioritize work in a scrum backlog then pull a subset of that work into a sprint, a fixed length of time to complete a specific body of work. Sprint planning is the process of deciding what tasks go from the backlog to the next sprint.
Step 3 - Use Git-based source control
Version control is a DevOps best practice that enables greater collaboration and faster release cycles. Tools like Bitbucket allow developers to share, collaborate, merge, and backup software.
Pick a branching model. This article provides an overview of the concept. GitHub flow is a great starting point for teams new to Git as it is simple to understand and easy to implement. Trunk-based development is often preferred but requires more discipline and makes for a more difficult first foray into Git.
Step 4 - Integrate source control with work tracking
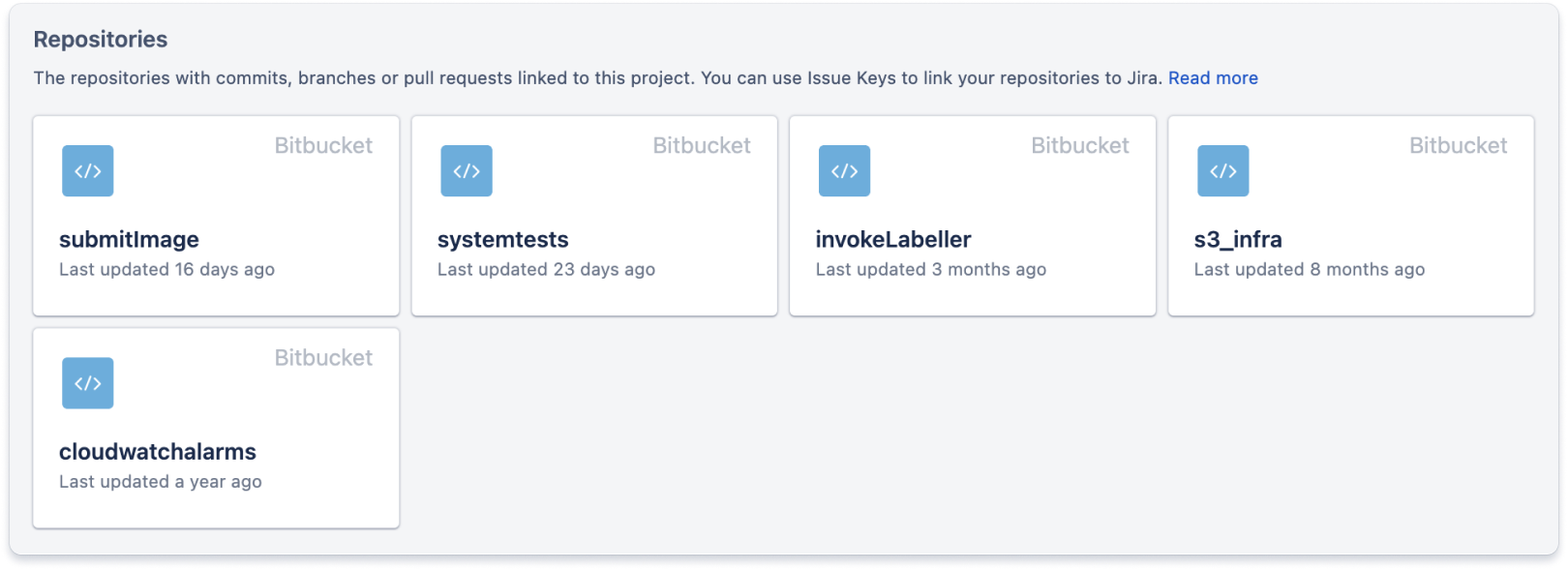
Integrate the source control tool with the work tracking tool. By having a single place to see everything related to a particular project, developers and management will save a significant amount of time. Below is an example of a Jira issue with updates from a Git-based source control repository. Jira issues include a development section that aggregates work done for the Jira issue in source control. This issue had a single branch, six commits, one pull request, and a single build.
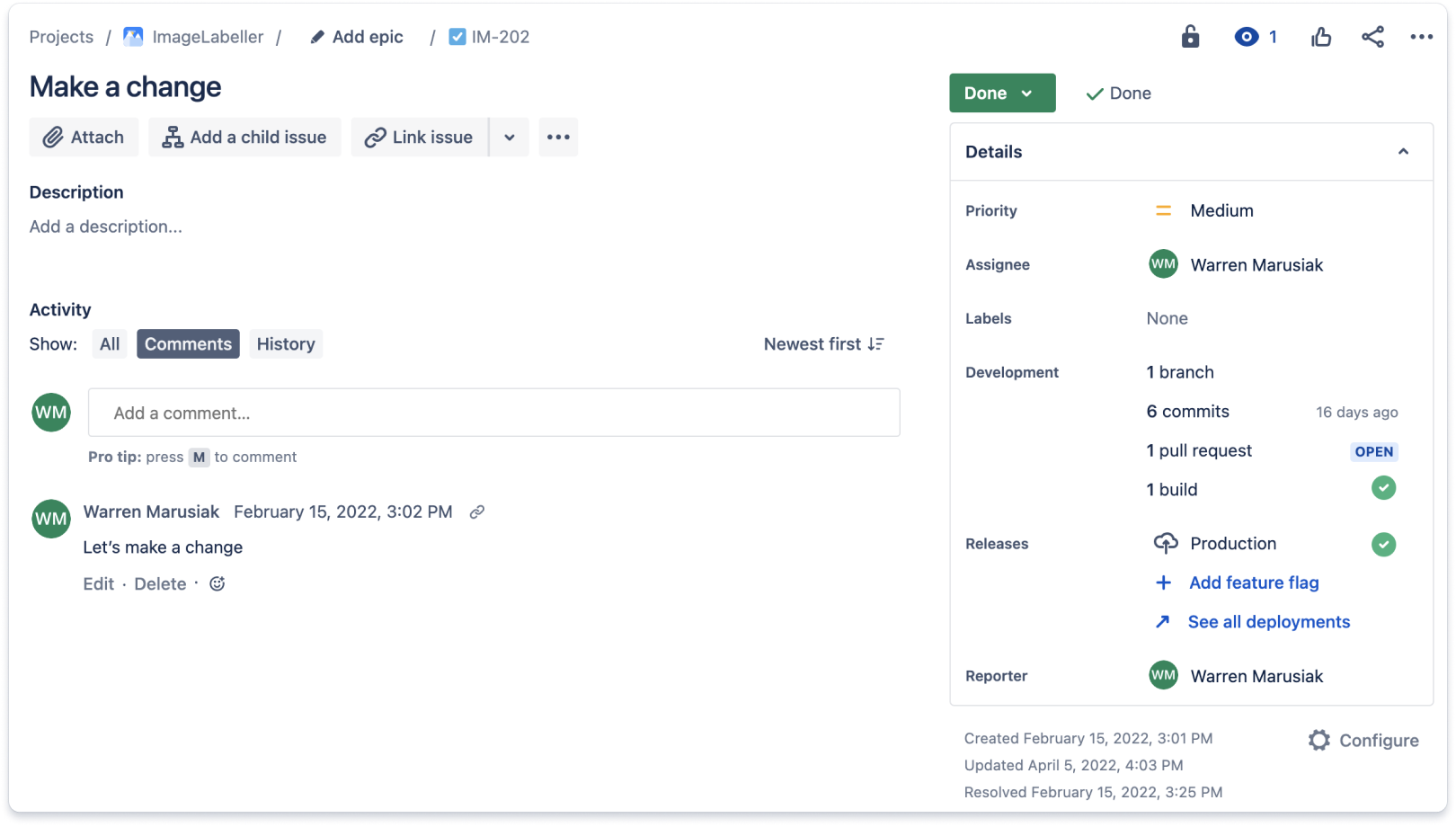
You can find additional details by drilling into the development section of a Jira issue. The commits tab lists all commits associated with a Jira issue.

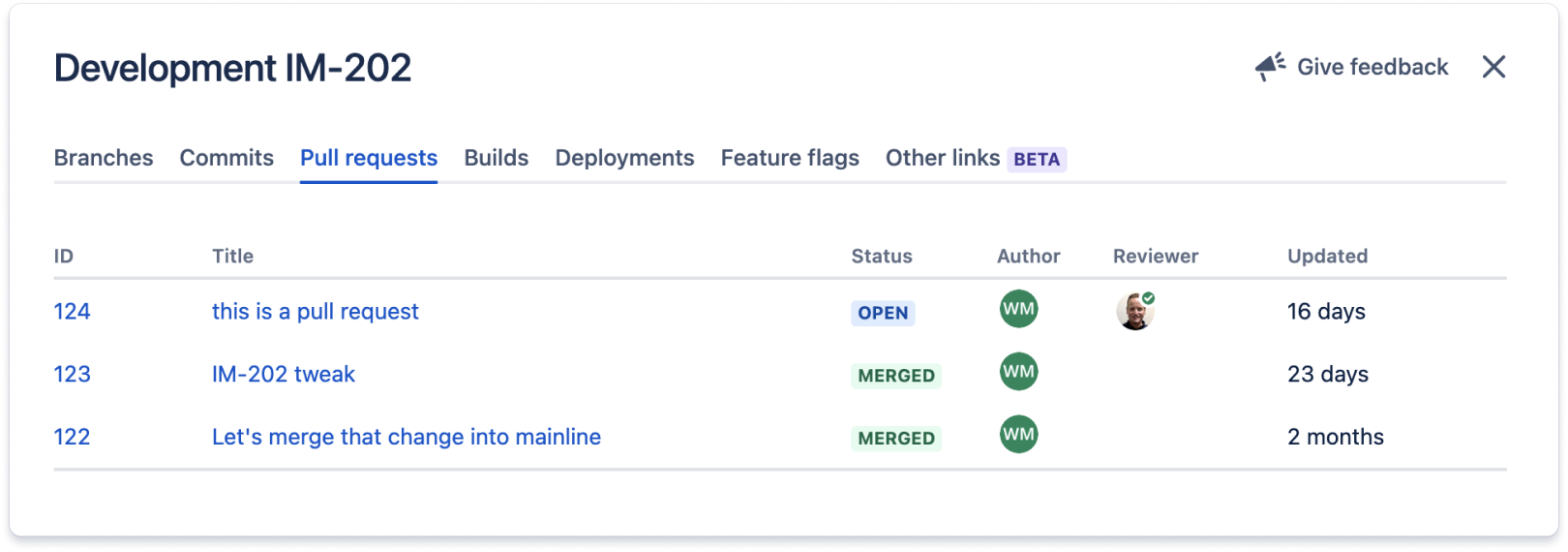
The code related to this Jira issue is deployed to all environments listed in the Deployments section. These integrations usually work by adding the Jira issue ID – in this case IM-202 – to commit messages and branch names of work related to the Jira issue.
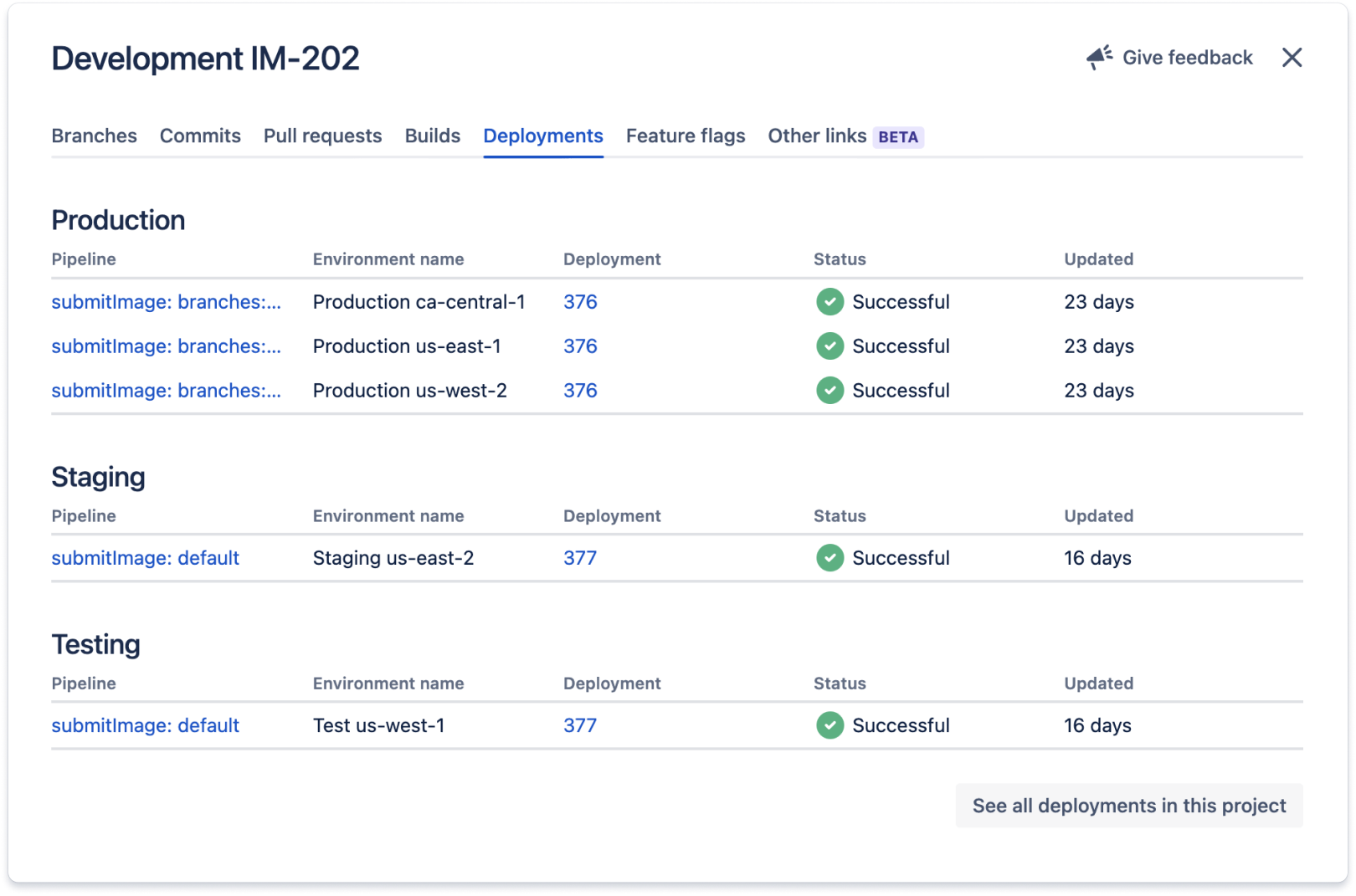
There is a code tab that provides links to all source control repositories related to the project. This helps developers find the code they need to work on when they assign themselves to a Jira issue.
Step 5 - Write tests
CI/CD pipelines need tests to validate that the code deployed to various environments works correctly. Start by writing unit tests for the code. While an ambitious goal is 90 percent code coverage, this is unrealistic when just beginning. Set a low baseline for code coverage and incrementally increase the bar for unit test coverage over time. You can add work items to the backlog to address this.
Use test-driven development when fixing bugs found in production code. When you find a bug, write unit tests, integration tests, and/or system tests that fail in environments where the bug is live. Then fix the bug and observe that the tests now pass. This process will organically increase code coverage over time. If the bug was caught in a test or staging environment, the tests will give confidence that the code is working properly when promoted to production.
When starting from the beginning, this step is labor intensive but important. Testing allows teams to see the effect of code changes on the behavior of the system before exposing end-users to those code changes.
Unit tests
Unit tests verify the source code is correct and should be run as one of the first steps in a CI/CD pipeline. Developers should write tests for the green path, problematic inputs, and known corner cases. When writing the tests, developers can mock the inputs and expected outputs.
Integration tests
Integration tests verify that two components communicate with each other correctly. Mock the inputs and expected outputs. These tests are one of the first steps of a CI/CD pipeline before deploying to any environment. These tests typically require more extensive mocking than unit tests to get them to work.
System tests
System tests verify the end-to-end performance of the system and provide confidence that the system is working as expected in each environment. Mock the input that a component might receive and execute the system. Next, verify that the system returns the necessary values and updates the rest of the system correctly. These tests should be run after deployment to each environment.
Step 6 - Build out a CI/CD process to deploy the component
Consider deploying to multiple environments when building out a CI/CD pipeline. Things will get hardcoded if a team builds a CI/CD pipeline that deploys to only a single environment. It is important to build CI/CD pipelines for infrastructure and code. Start by building a CI/CD pipeline to deploy the necessary infrastructure in each environment. Then, build another CI/CD pipeline to deploy the code.
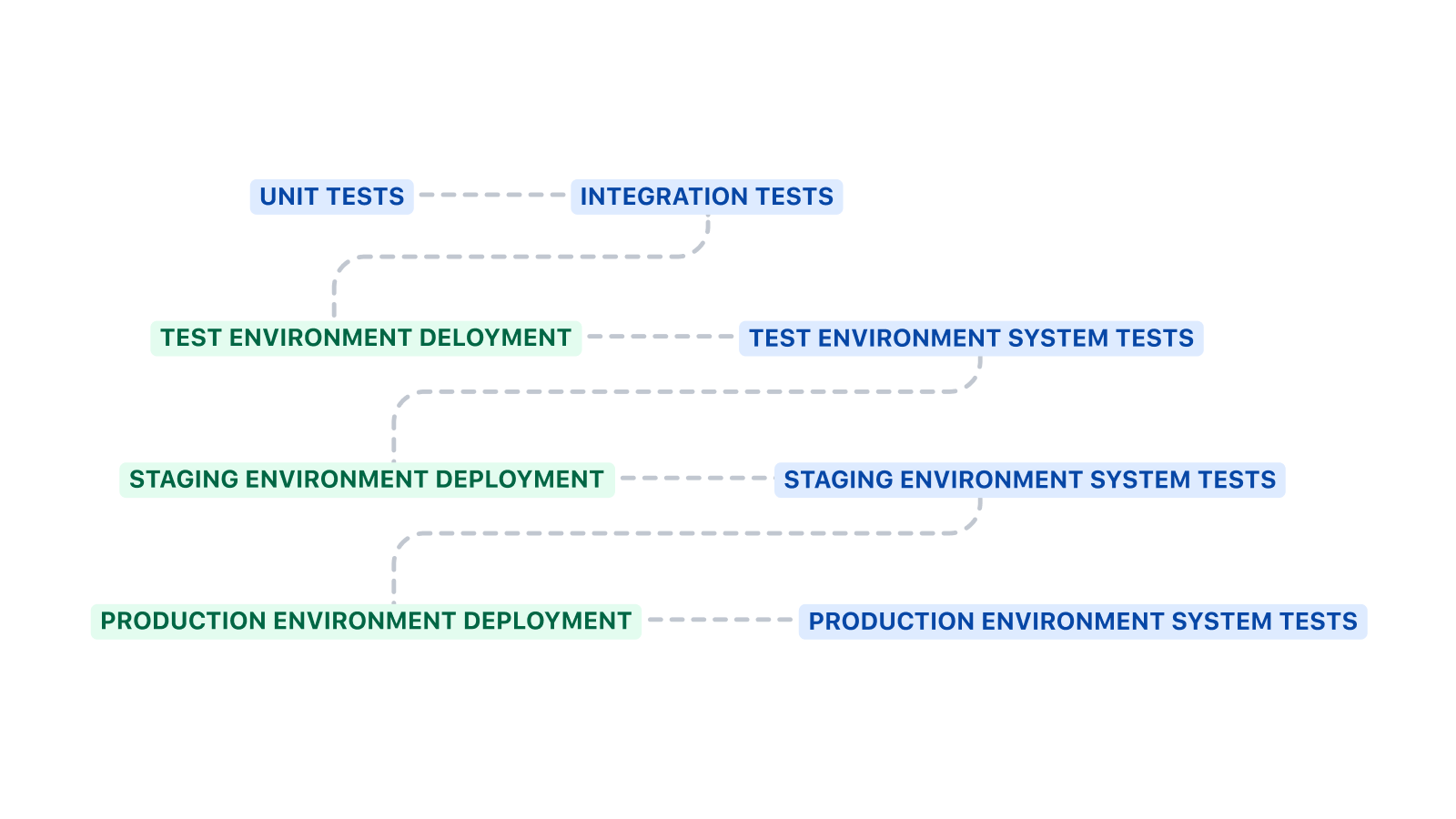
Pipeline structure
This pipeline starts by running unit tests and integration tests before deploying to the test environment. System tests are executed after deploying to an environment.
The rough template above can be expanded in several ways. Code linting, static analysis, and security scanning are good additional steps to add before unit and integration tests. Code linting can enforce coding standards, static analysis can check for anti-patterns, and security scanning can detect the presence of known vulnerabilities.
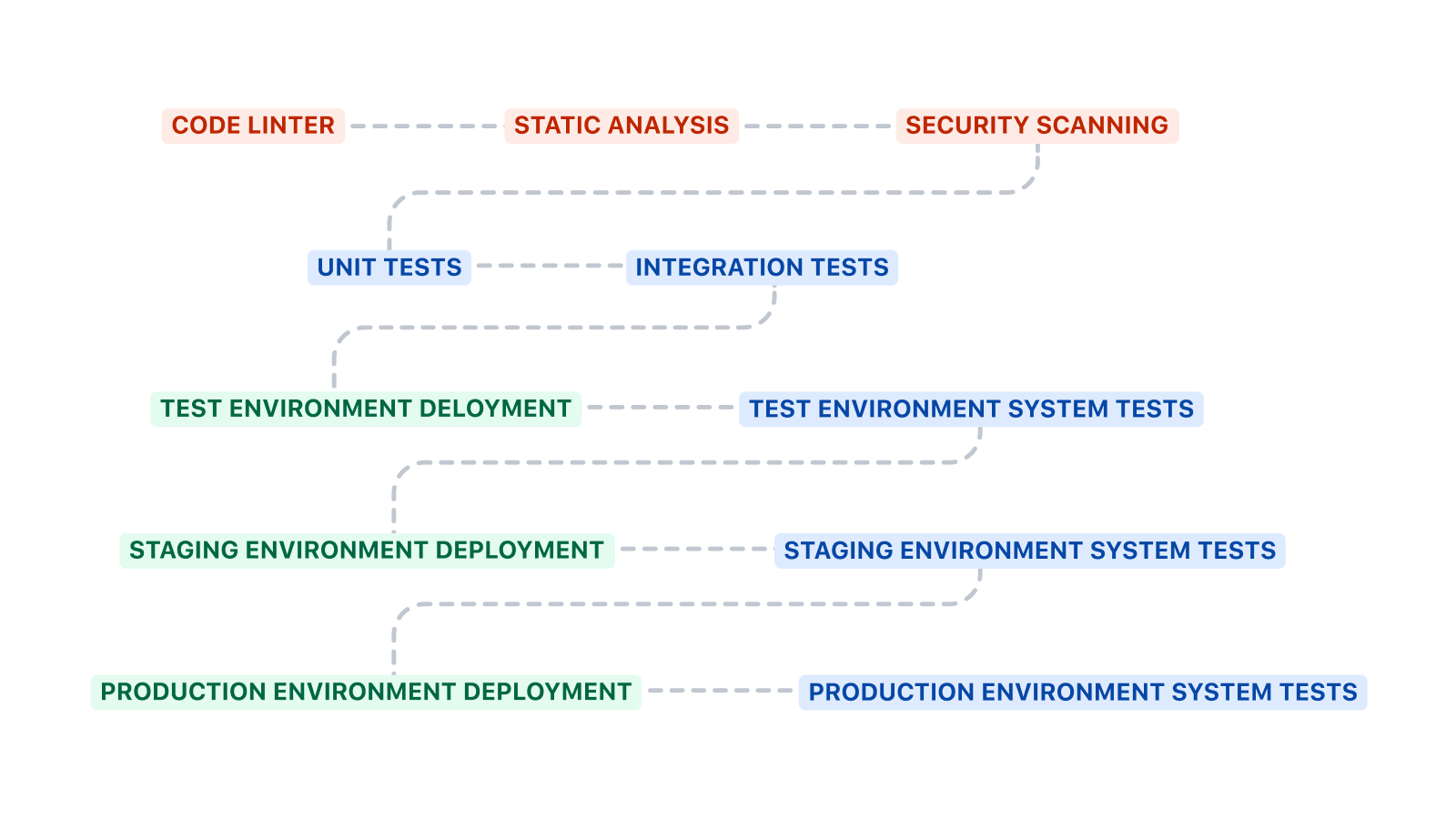
The CI/CD pipelines for deploying infrastructure and code are likely different. The CI/CD pipeline for infrastructure often does not have unit or integration tests. It will run the system tests after every deployment to ensure the system hasn’t stopped working.
Infrastructure
Differences in infrastructure between environments make it difficult for the software running in that environment to execute correctly. Firewall rules, user permissions, database access, and other infrastructure-level components must be in a known configuration for software to execute properly. Manual infrastructure deployment can be challenging to repeat correctly. Since this process has many steps, remembering to execute each step in the correct order, with the right parameters, can lead to errors. Infrastructure must be defined in code wherever possible to alleviate these and other problems.
Infrastructure can be defined in code by a variety of tools, including AWS CloudFormation, Terraform, Ansible, Puppet, or Chef.
Write multiple pipelines to deploy the infrastructure. Like writing code, it is helpful to keep infrastructure deployment modular. Decompose the required infrastructure into disjoint subsets where possible. Suppose A, B, C, and D are abstractions for infrastructure components that can depend on each other. For example, A could be an EC2 box and B could be an S3 bucket. Dependencies where an infrastructure component A – and only A – depend on component B should likely be kept together in the same CI/CD pipeline. Dependencies where A, B, and C depend on D – but A, B, and C are independent – should be broken into multiple CI/CD pipelines. In this case, four independent pipelines. In this instance, you should build one pipeline for D that all three other components depend on, and one for each of A, B, and C.
Code
CI/CD pipelines are built to deploy code. These pipelines are usually straightforward to implement since the infrastructure is already available due to earlier work. Important considerations here are testing, repeatability, and an ability to recover from bad deployments.
Repeatability is the ability to deploy the same changeover and over again without harming the system. The deployment should be re-entrant and idempotent. A deployment should set the state of a system to a known configuration rather than apply a modifier to the existing state. Applying a modifier cannot be repeated since, after the first deployment, the necessary starting state for the modifier to function properly changed.
A simple example of a non-repeatable update is updating a configuration file by appending data to it. Don't append rows to configuration files or use any such modification technique. The configuration file can end up with dozens of duplicate rows if updates are done via append. Instead, replace the configuration file with a correctly written file from source control.
This principle should also be applied to updating databases. Database updates can be problematic and require attention to detail. It is essential to make the database update process repeatable and fault tolerant. Take backups immediately before applying changes so that recovery is possible.
Another consideration is how to recover from a bad deployment. Either the deployment failed and the system is in an unknown state, or the deployment succeeded, alarms are triggered, and trouble tickets start flowing in. There are two general ways of dealing with this. The first is to do a rollback. The second is to use feature flags and toggle the necessary flags off to return to a known good state. See Step 8 of this article for more information about feature flags.
A rollback deploys the previously known good state to an environment after a bad deployment is detected. This should be planned for in the beginning. Before touching a database, take a backup. Make sure you can quickly deploy the previous version of the code. Test the rollback process in Test or Staging environments regularly.
Step 7 - Add monitoring, alarms, and instrumentation
A DevOps team needs to monitor the behavior of the running application in each environment. Are there errors in the logs? Are calls to APIs timing out? Are databases crashing? Monitor each component of the system for problems. If monitoring detects a problem, raise a trouble ticket so that someone can resolve the problem. As part of the resolution, write additional tests that can catch the problem.
Fixing bugs
Monitoring and responding to problems is part of running production software. A team with a DevOps culture owns the operation of the software and borrows the behaviors of a site-reliability engineer (SRE). Do root cause analysis of the problem, write tests to detect the problem, fix the problem, and verify that the tests now pass. This process is often laborious up front but pays dividends in the long run since it reduces technical debt and operational agility is maintained.
Performance optimization
Once basic health monitoring is in place, performance tuning is a frequent next step. Look at how each piece of a system runs and optimize the slow pieces. As Knuth noted: “premature optimization is the root of all evil.” Don’t optimize the performance of everything in the system. Only optimize the slowest, most costly pieces. Monitoring helps identify which components are slow and costly.
Step 8 - Use feature flags to implement canary testing
To enable canary testing, wrap each new feature in a feature flag with an allow list that contains test users. The new feature code will only run for the users in the allow list once deployed to an environment. Let the new feature soak in each environment before promoting it to the next. While the new feature soaks in a region, pay attention to metrics, alarms, and other instrumentation for signs of problems. Specifically, look for an uptick in new trouble tickets.
Address problems in an environment before promoting them to the next environment. Problems found in the production environments should be handled the same as problems in test or staging environments. Once you identify the root cause of the problem, write tests to identify the problem, implement a fix, verify the tests pass, and promote the fix through the CI/CD pipeline. The new tests will pass and the trouble ticket count will drop while the change soaks in the environment where the problem was detected.
In conclusion...
Do a retrospective of the project for moving the first component into DevOps. Identify the pain points, or parts that were challenging or difficult. Augment the plan to address these pain points and then move on to the second component.
Using a DevOps approach to get a component to production may seem like a substantial amount of work in the beginning but it pays dividends later. Implementing the second component should be easier once the groundwork is established. The same process for the first component can be used and slightly modified for the second component since the tools are in place, the technologies are understood, and the team is trained to work in a DevOps style
To start your journey with DevOps, we recommend trying Atlassian Open DevOps, an integrated and open toolchain with everything you need to develop and operate software, and the ability to integrate additional tools as your needs grow.
Was this helpful?
Thanks!
Warren Marusiak

11 comments